Apache Samza is a powerful distributed stream processing framework designed for building scalable and fault-tolerant real-time data processing applications. To help you ace your Samza interviews, we’ve compiled a list of the top 30 questions and answers.
1. What is Apache Samza?
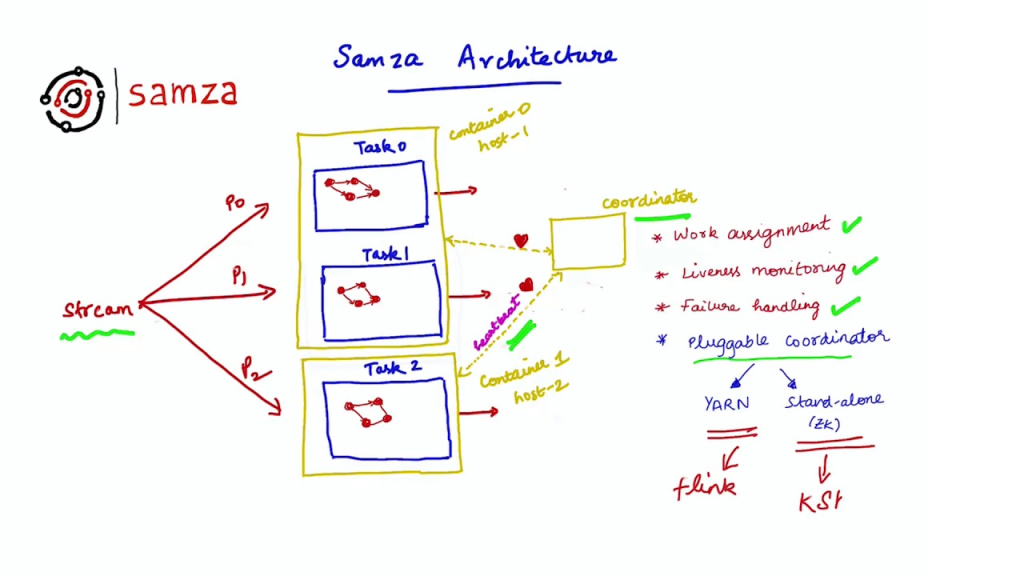
Apache Samza is an open-source distributed stream processing framework that enables you to process real-time data streams from various sources like Kafka, Kinesis, or custom sources. It’s designed to handle high-throughput and low-latency data processing.

2. What are the core components of Apache Samza?
Samza’s core components include:
- Container: The execution environment for Samza jobs.
- Task: The unit of work that processes incoming data.
- System: Manages the overall execution of Samza jobs.
- Job: A collection of tasks that work together to process data.
- Stream: A continuous, unbounded sequence of records.
3. How does Samza ensure fault tolerance and scalability?
Samza employs several mechanisms to ensure fault tolerance and scalability:
- Task Failures: Samza automatically restarts failed tasks.
- Container Failures: Samza automatically restarts failed containers.
- State Management: Samza uses a distributed state store to persist state information.
- Scalability: Samza can scale horizontally by adding more containers to the cluster.
4. What is the role of Samza’s state store?
The state store is a key component of Samza, allowing tasks to maintain state information across multiple invocations. It ensures data consistency and enables stateful computations.
5. How does Samza handle data partitioning and parallelism?
Samza partitions input streams into multiple partitions, and each task processes a specific partition. This allows for parallel processing and scalability.
6. What is the concept of a Samza job?
A Samza job is a collection of tasks that work together to process data. It defines the data flow, the transformations to be applied, and the output format.
7. How does Samza integrate with other systems?
Samza can integrate with a variety of systems, including Kafka, HDFS, and other big data technologies. It can also be integrated with external systems using custom connectors.
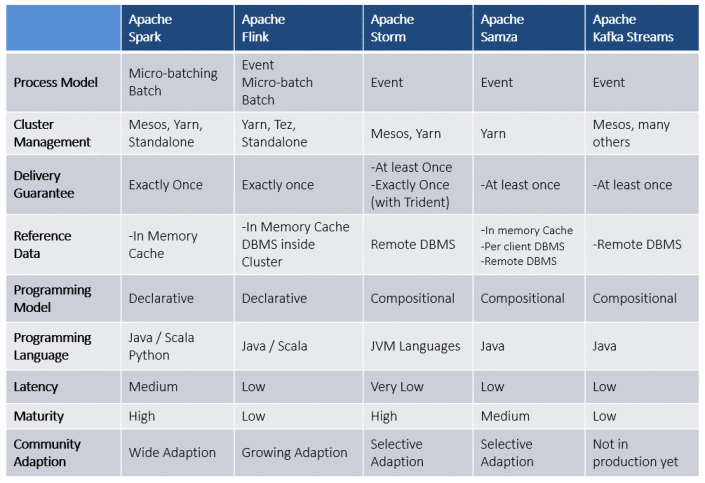
8. What is the difference between Samza and Kafka Streams?
While both Samza and Kafka Streams are stream processing frameworks, they have some key differences:
- Samza: More flexible and powerful, but requires more configuration and management.
- Kafka Streams: Simpler to use, but less flexible than Samza.
9. What is the role of the Samza System?
The Samza System is responsible for managing the overall execution of Samza jobs. It handles tasks, containers, and the state store.
10. How does Samza handle data consistency and exactly-once processing?
Samza ensures data consistency and exactly-once processing through its state store and checkpointing mechanisms.
11. What are the key challenges in using Apache Samza?
Some of the challenges in using Samza include:
- Steep learning curve: Samza has a complex architecture and requires a deep understanding of distributed systems.
- Operational overhead: Samza requires careful configuration and management.
- Limited community support: Compared to other frameworks like Kafka Streams, Samza has a smaller community.
12. How do you monitor and troubleshoot Samza jobs?
Samza provides various tools and metrics for monitoring and troubleshooting:
- Samza Metrics: Monitor the performance of tasks and containers.
- Logging: Analyze logs to identify issues.
- Visualizations: Use tools like Grafana to visualize metrics and trends.
13. How do you optimize Samza performance?
To optimize Samza performance, consider the following:
- Partitioning: Partition data effectively to maximize parallelism.
- Task Configuration: Tune task configurations to optimize resource utilization.
- State Store Optimization: Choose the right state store and optimize its configuration.
- Network Optimization: Optimize network configuration and reduce latency.
14. How do you handle data security and privacy in Samza?
Samza can be secured using various mechanisms, including:
- Authentication and Authorization: Control access to Samza clusters.
- Data Encryption: Encrypt sensitive data at rest and in transit.
- Network Security: Secure network communication between Samza components.
15. What is the role of Samza’s task scheduler?
The Samza task scheduler is responsible for assigning tasks to containers and managing their execution. It ensures efficient resource utilization and fault tolerance.
16. How do you handle backpressure in Samza?
Samza uses backpressure mechanisms to prevent data overload and ensure smooth data flow. It can slow down upstream components or drop data if necessary.
17. What is the difference between Samza and Flink?
While both Samza and Flink are powerful stream processing frameworks, they have some key differences:
- Samza: More mature and stable, but requires more configuration and management.
- Flink: More flexible and easier to use, but may have higher resource requirements.
18. How do you handle stateful computations in Samza?
Samza’s state store allows you to maintain state information across multiple invocations of a task. This enables stateful computations like windowing, aggregation, and joins.
19. What is the role of Samza’s checkpointing mechanism?
Samza’s checkpointing mechanism ensures data consistency and fault tolerance by periodically saving the state of tasks to a persistent store.
20. How do you integrate Samza with external systems?
Samza can integrate with a variety of external systems through connectors and APIs. It can also be integrated with other big data tools like Hadoop and Spark.
21. What are some common use cases of Apache Samza?
Samza is used in a variety of applications, including:
- Real-time analytics: Analyzing data streams in real-time to generate insights.
- Data ingestion and transformation: Ingesting data from various sources and transforming it into a desired format.
- Fraud detection: Detecting fraudulent activities by analyzing real-time data streams.
- IoT data processing: Processing data from IoT devices.
- Log processing and analysis: Analyzing log data in real-time.
22. How do you optimize Samza for low-latency processing?
To optimize Samza for low-latency processing, consider the following:
- Minimize data serialization and deserialization: Use efficient serialization formats.
- Reduce network latency: Optimize network configuration and reduce data transfer.
- Optimize task configuration: Tune task configurations to minimize processing time.
- Use efficient state stores: Choose state stores that are optimized for low-latency access.
23. How do you handle data security and privacy in Samza?
Samza can be secured using various mechanisms, including:
- Authentication and Authorization: Control access to Samza clusters.
- Data Encryption: Encrypt sensitive data at rest and in transit.
- Network Security: Secure network communication between Samza components.
24. What are some best practices for using Apache Samza?
- Design your data flow carefully: Consider data sources, transformations, and destinations.
- Modularize your tasks: Break down complex tasks into smaller, reusable components.
- Monitor and troubleshoot your jobs: Keep an eye on your jobs and identify and resolve issues promptly.
- Optimize resource utilization: Configure Samza to efficiently use resources.
- Consider security best practices: Protect your data and infrastructure.
25. How do you handle errors and failures in Samza?
Samza provides mechanisms for handling errors and failures, including:
- Task failures: Samza automatically restarts failed tasks.
- Container failures: Samza automatically restarts failed containers.
- Error handling in tasks: Implement error handling logic within tasks.
- Logging and monitoring: Use logs and metrics to identify and troubleshoot issues.
26. How do you handle data consistency in Samza?
Samza ensures data consistency through its state store and checkpointing mechanisms. This guarantees that data is processed exactly once, even in the event of failures.
27. How do you integrate Samza with other big data tools?
Samza can be integrated with other big data tools like Hadoop, Spark, and Kafka through connectors and APIs. This allows you to build complex data pipelines and analytics workflows.
28. What are some common challenges in deploying Samza in production?
Some common challenges in deploying Samza in production include:
- Cluster management: Managing a large Samza cluster can be complex.
- Configuration: Configuring Samza can be challenging, especially for complex setups.
- Monitoring and troubleshooting: Monitoring and troubleshooting Samza jobs can be time-consuming.
29. What is the future of Apache Samza?
While Samza is a powerful framework, it faces competition from newer frameworks like Flink and Kafka Streams. However, Samza continues to evolve and improve, and it remains a viable option for building scalable and fault-tolerant stream processing applications.
30. What are some tips for writing efficient Samza jobs?
- Optimize data serialization and deserialization: Choose efficient serialization formats like Avro or Protobuf.
- Minimize network traffic: Reduce the amount of data transferred between tasks.
- Use efficient state stores: Choose state stores that are optimized for your use case.
- Monitor and tune performance: Use metrics and logs to identify performance bottlenecks.
- Write clean and maintainable code: Use clear and concise code to improve readability and maintainability.