DataOps is gaining momentum as a critical approach to managing and optimizing data workflows in Big Data and AI projects. As data complexity grows, DataOps offers an efficient way to handle data at scale, improve collaboration, and speed up insights. This blog explores the essential role of DataOps in advancing Big Data and AI initiatives, ensuring they’re efficient, agile, and effective.

1. Understanding DataOps in the Context of Big Data and AI
- What is DataOps?
DataOps is a methodology that applies Agile principles and DevOps practices to data workflows, focusing on automation, collaboration, and continuous improvement. It brings order and efficiency to the complex workflows needed for Big Data and AI. - Why DataOps in Big Data and AI?
Big Data and AI projects require vast amounts of high-quality, up-to-date data. DataOps enables streamlined data handling, so teams can quickly access and use data for model training, analysis, and insight generation.
2. The Challenges of Big Data and AI Projects Without DataOps
Big Data and AI projects face unique challenges that can hinder success without a structured approach like DataOps:
- Data Complexity and Volume: Big Data projects must process massive volumes and diverse types of data, which can quickly lead to data quality issues and processing bottlenecks.
- Collaboration Across Teams: AI projects often involve data scientists, engineers, and business analysts who need a collaborative framework to work seamlessly.
- Manual, Time-Consuming Processes: Traditional data workflows are prone to errors and delays, making it difficult for AI projects to operate at the pace required.

3. Key Benefits of DataOps for Big Data and AI
DataOps provides several essential benefits that support the unique needs of Big Data and AI projects:
a. Automated Data Pipelines for Efficiency
- End-to-End Automation: DataOps automates data ingestion, processing, and transformation, making data consistently available for analysis or model training.
- Error Reduction: Automation reduces human errors, ensuring high-quality data flows into Big Data and AI projects without delays or inconsistencies.
b. Enhanced Data Quality and Governance
- Built-in Quality Checks: DataOps integrates validation and testing into data pipelines, ensuring data accuracy and reliability for AI model training and decision-making.
- Governance and Compliance: With centralized management of data pipelines, DataOps enables better governance, providing audit trails and compliance tracking.
c. Real-Time Data Access for AI Models
- Continuous Data Availability: DataOps pipelines facilitate real-time data access, making it easier to feed AI models with up-to-date information for more accurate predictions.
- Faster Model Iterations: AI projects rely on rapid model testing and retraining, and DataOps provides the consistent data needed to make this process agile.
d. Improved Collaboration Across Data Teams
- Cross-Functional Integration: DataOps fosters a collaborative environment for data engineers, scientists, and business users, allowing them to work together with shared visibility and goals.
- Streamlined Communication: By centralizing data operations, DataOps enhances communication and reduces silos, making it easier for teams to align on project goals.
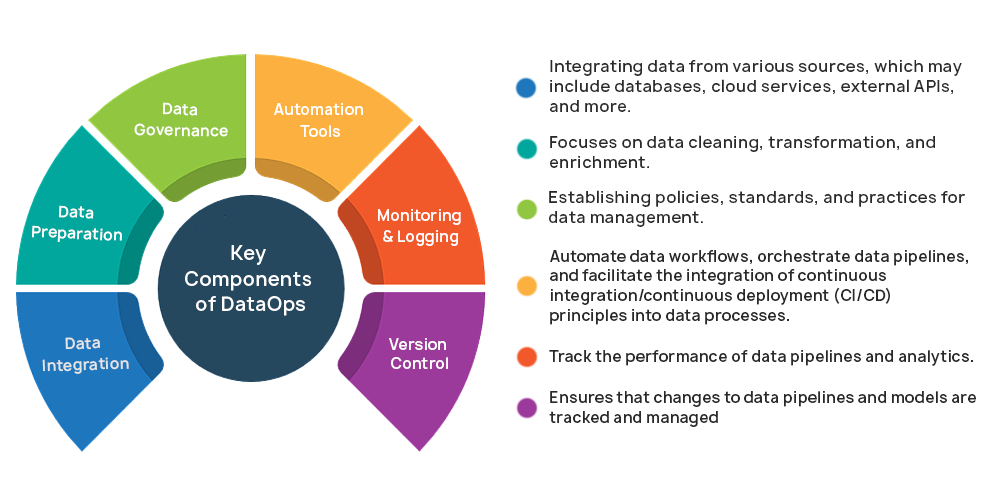
4. DataOps Practices that Drive Success in Big Data and AI
To achieve these benefits, DataOps employs practices that streamline Big Data and AI workflows:
a. Data Pipeline Automation
- Tools like Apache Airflow and dbt automate tasks from data extraction to transformation, making sure that Big Data and AI projects always have fresh, reliable data.
- Scheduled Data Flows: DataOps allows for scheduled data flows, so pipelines can run at optimal times without manual intervention.
b. Continuous Testing and Validation
- Automated Testing: DataOps integrates data quality tests and validation steps to catch errors early, ensuring that only clean, consistent data reaches AI models.
- Schema Validation: Automated schema validation detects any structural inconsistencies in incoming data, preventing corrupt data from entering the analysis or training phases.
c. Data Lineage and Version Control
- Track Data Transformations: With DataOps, organizations can track every transformation applied to data, helping teams understand data lineage and make informed adjustments.
- Version Control for Data Pipelines: DataOps employs version control for pipeline scripts and configurations, allowing teams to revert to previous states if issues arise.
d. Real-Time Monitoring and Alerting
- Proactive Monitoring: Tools like Grafana and Prometheus enable continuous monitoring of data pipelines, alerting teams to any potential issues in real-time.
- Automated Alerts: DataOps can trigger alerts when anomalies are detected, ensuring fast response times and reducing the impact of errors on AI model performance.
5. Implementing DataOps in Big Data and AI Projects
To incorporate DataOps in Big Data and AI projects, organizations can follow these steps:
- Adopt Agile and DevOps Principles: Build a foundation of Agile principles, focusing on iterative improvements, quick feedback loops, and continuous delivery.
- Choose DataOps Tools: Select tools that support DataOps practices, such as Apache NiFi, dbt, and Kafka for automation, and Snowflake or AWS Glue for data storage and processing.
- Foster a Collaborative Environment: Encourage collaboration between data engineers, scientists, and business analysts to align on goals and processes.
- Establish Governance and Compliance Standards: Define clear data governance policies and integrate compliance checks directly into DataOps workflows.