Processing and Machine Learning
Apache Spark is a powerful, general-purpose cluster computing system used extensively for big data processing, analytics, and machine learning. In this blog, we will explore the top 30 questions and answers that will help you understand how Apache Spark works and how it can be utilized in data processing and analytics.
1. What is Apache Spark?
Answer: Apache Spark is a fast and general-purpose cluster computing system that enables large-scale data processing. It offers in-memory processing capabilities and supports a wide range of applications, including data analytics, machine learning, and real-time stream processing.
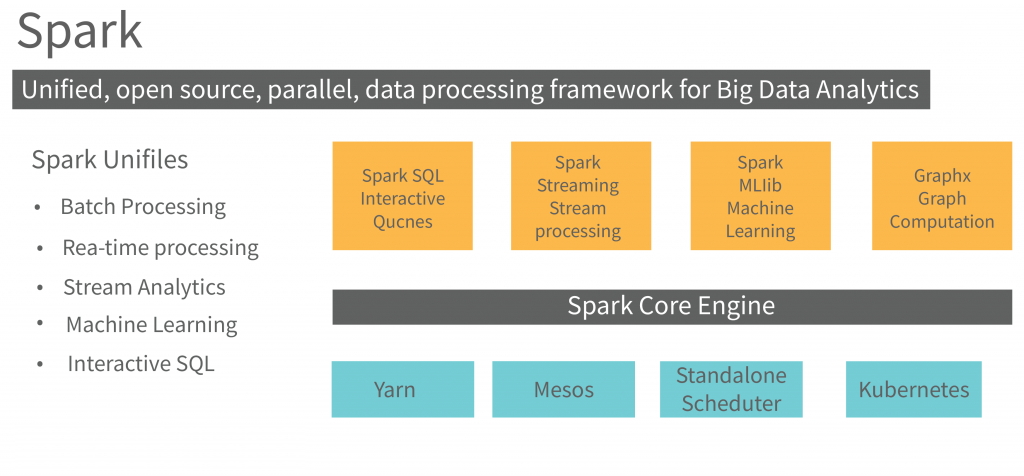
2. What are the key features of Apache Spark?
Answer: Key features include in-memory data processing, fault tolerance, ease of use with high-level APIs in multiple languages (Scala, Java, Python, R), scalability across clusters, support for batch and stream processing, and machine learning integration through MLlib.
3. How does Apache Spark differ from Hadoop?
Answer: While both Spark and Hadoop are used for big data processing, Spark processes data in memory, which makes it significantly faster than Hadoop’s MapReduce. Hadoop uses disk-based storage, which can slow down computations.
4. What are Resilient Distributed Datasets (RDDs)?
Answer: RDDs are the fundamental data structure in Apache Spark. They are fault-tolerant collections of data that can be processed in parallel across a cluster.
5. What is Spark SQL?
Answer: Spark SQL is a module in Apache Spark that allows users to run SQL queries on structured and semi-structured data. It provides an interface to connect Spark with various databases and data sources.
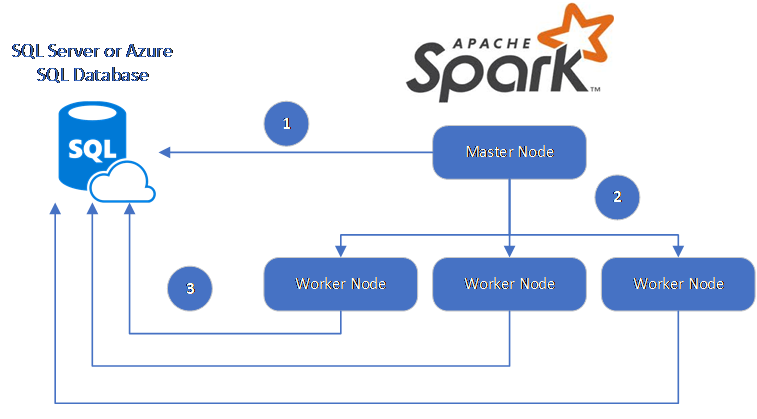
6. What is the difference between RDD and DataFrame in Spark?
Answer: RDDs are low-level data abstractions, while DataFrames are a higher-level abstraction that provides a tabular format similar to a database table, offering optimizations like catalyst and tungsten for better performance.
7. What is a Spark job?
Answer: A Spark job is an execution of a series of transformations and actions on an RDD or DataFrame. It consists of multiple tasks that run across a cluster.
8. How does Apache Spark achieve fault tolerance?
Answer: Spark achieves fault tolerance using lineage graphs. If a node fails, Spark can rebuild lost RDDs from their original source using the lineage information.
9. What are transformations and actions in Spark?
Answer: Transformations are operations that create a new RDD from an existing one (e.g., map, filter), while actions are operations that trigger computation and return a value (e.g., collect, count).
10. What is the SparkContext?
Answer: SparkContext is the entry point for a Spark application. It represents the connection to a Spark cluster and is used to configure the application.
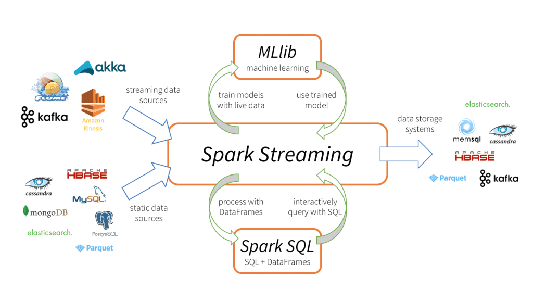
11. How does Apache Spark support machine learning?
Answer: Spark provides the MLlib library, which offers scalable machine learning algorithms, including classification, regression, clustering, collaborative filtering, and more. It integrates seamlessly with Spark’s distributed computing framework.
12. What is Spark Streaming?
Answer: Spark Streaming is a component of Spark that allows for real-time data stream processing. It processes data in micro-batches, enabling near-real-time analytics.
13. What is a DAG (Directed Acyclic Graph) in Spark?
Answer: A DAG in Spark represents a series of operations performed on data, with each node representing a stage in the computation. Spark’s DAG scheduler breaks these stages into tasks that are distributed across the cluster.
14. What is the difference between Spark Core and Spark SQL?
Answer: Spark Core is the underlying engine responsible for job scheduling, memory management, and fault tolerance, while Spark SQL is a module that adds support for structured data processing using SQL.
15. What are partitions in Apache Spark?
Answer: Partitions are logical divisions of data within an RDD or DataFrame. They allow Spark to distribute data across different nodes in a cluster and perform parallel processing.
16. What is PySpark?
Answer: PySpark is the Python API for Apache Spark, allowing Python developers to interface with Spark and use its capabilities for big data processing.
17. How does Spark handle data shuffling?
Answer: Data shuffling is the process of redistributing data across partitions. It is expensive in terms of performance, but Spark optimizes this using operations like reduceByKey, which minimize the amount of shuffled data.
18. What are accumulators and broadcast variables in Spark?
Answer: Accumulators are variables used to aggregate information across executors, while broadcast variables are used to distribute read-only data efficiently to all nodes.
19. Can Spark handle both batch and real-time processing?
Answer: Yes, Apache Spark can handle both batch processing (using RDDs, DataFrames, and Datasets) and real-time stream processing (using Spark Streaming or Structured Streaming).
20. What is Structured Streaming in Spark?
Answer: Structured Streaming is an extension of Spark SQL that enables scalable and fault-tolerant stream processing. It allows users to process streaming data in a way that is similar to batch processing.
21. What is the Catalyst Optimizer in Spark?
Answer: The Catalyst Optimizer is a component in Spark SQL that optimizes query plans and improves the performance of SQL queries on DataFrames and Datasets.
22. How does Spark integrate with Hadoop?
Answer: Spark can integrate with Hadoop’s distributed file system (HDFS) for storage and YARN for cluster resource management. It can also process data stored in HBase, Hive, and other Hadoop ecosystem tools.
23. How is Spark different from Flink?
Answer: Both Spark and Flink are used for big data processing, but Spark processes data in micro-batches, while Flink handles true stream processing by processing data one event at a time.
24. What is Spark’s Cluster Manager?
Answer: The Cluster Manager is responsible for managing resources across the cluster in Spark. It can be standalone, or Spark can integrate with resource managers like Apache Mesos or Hadoop YARN.
25. How does Spark handle memory management?
Answer: Spark handles memory through unified memory management. It divides memory between execution (storing intermediate results) and storage (caching RDDs or DataFrames).
26. How do you tune Spark performance?
Answer: Spark performance can be tuned by optimizing memory usage (adjusting executor memory), reducing shuffle operations, using DataFrames/Datasets instead of RDDs, and managing partition sizes effectively.
27. What are the use cases for Apache Spark?
Answer: Spark is used in use cases such as big data analytics, real-time data processing, machine learning, ETL pipelines, graph processing, and stream processing.

28. How can Spark be deployed on the cloud?
Answer: Spark can be deployed on cloud platforms like AWS, Azure, and Google Cloud using services like AWS EMR, Azure HDInsight, or Google Dataproc for scalable big data processing.
29. How does Spark support graph processing?
Answer: Spark provides the GraphX library, which supports graph computation and offers APIs for building and processing graphs, including algorithms like PageRank, Connected Components, and others.
30. What is the future of Apache Spark?
Answer: Apache Spark continues to evolve with improvements in streaming (Structured Streaming), deeper integration with machine learning and AI tools, better cloud support, and optimized query engines for large-scale data processing.