Apache Storm is a real-time, distributed stream processing system that efficiently handles high-velocity, high-volume data streams. It is designed for fast, scalable, and fault-tolerant data processing. In this blog, we will explore the 30 top questions and answers that will help you better understand how Apache Storm works and how it can be used in real-time data processing.
1. What is Apache Storm?
Answer: Apache Storm is a distributed stream processing system that processes real-time data streams with low latency and high throughput. It is commonly used for big data, real-time analytics, and event processing.
2. What are the key features of Apache Storm?
Answer: Key features include real-time processing, fault tolerance, scalability, guaranteed message processing, horizontal scaling, and support for different programming languages through its robust APIs.
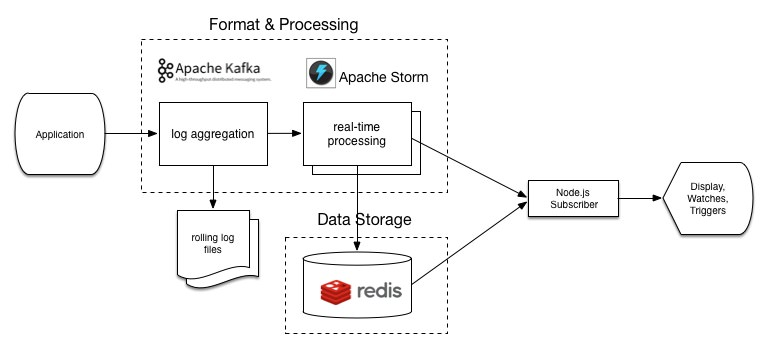
3. How does Apache Storm differ from batch processing systems?
Answer: Unlike batch processing systems, which process data in large chunks at scheduled intervals, Apache Storm processes data continuously as it arrives, making it ideal for real-time applications.
4. What are the core components of Apache Storm?
Answer: The core components include Spouts (data sources), Bolts (data processors), and Topologies (the entire data flow pipeline). These components work together to form a Storm application.
5. What is a Storm topology?
Answer: A Storm topology is the blueprint of a Storm application. It defines the flow of data through a network of Spouts and Bolts, specifying how data should be processed.
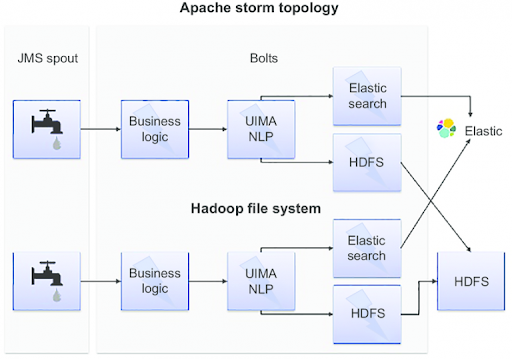
6. What is a Spout in Apache Storm?
Answer: A Spout is a data source that ingests streams of data into the Storm topology. It is responsible for emitting data tuples into the stream for further processing by Bolts.
7. What is a Bolt in Apache Storm?
Answer: A Bolt is a processing unit in a Storm topology. It can filter, transform, aggregate, or join data tuples that come from Spouts or other Bolts in the topology.
8. What is a tuple in Apache Storm?
Answer: A tuple is a named list of values representing a single unit of data in Apache Storm. It is the fundamental data structure that is passed between Spouts and Bolts.
9. How does Apache Storm ensure fault tolerance?
Answer: Apache Storm ensures fault tolerance by reassigning tasks to other nodes in the cluster if a node fails. It also has mechanisms to replay failed or unprocessed tuples, ensuring that no data is lost.
10. What is stream grouping in Apache Storm?
Answer: Stream grouping defines how tuples are distributed among the Bolts. Types of stream grouping include shuffle grouping (random distribution), fields grouping (based on field values), and global grouping (all tuples go to one Bolt).
11. How does Apache Storm handle backpressure?
Answer: Apache Storm handles backpressure by slowing down data ingestion when the processing units (Bolts) cannot keep up with the data flow. This prevents system overload and ensures consistent performance.
12. What is Trident in Apache Storm?
Answer: Trident is a high-level abstraction built on top of Apache Storm, providing stateful stream processing, exactly-once processing semantics, and transactional processing capabilities.
13. What is the role of the Nimbus node in Storm?
Answer: Nimbus is the master node in a Storm cluster. It is responsible for distributing tasks to worker nodes, monitoring the cluster’s health, and managing topology submissions.
14. What is the role of a Supervisor node in Storm?
Answer: A Supervisor node in Storm runs the worker processes. It receives tasks from Nimbus and coordinates the execution of topologies on worker nodes.
15. How does Apache Storm ensure guaranteed message processing?
Answer: Apache Storm ensures guaranteed message processing by using an acknowledgment (ACK) system. When a tuple is processed successfully, an acknowledgment is sent back to the Spout. If a tuple fails, it is replayed.
16. What is the difference between at-most-once and exactly-once processing in Storm?
Answer: At-most-once processing means that data may be lost but will not be processed more than once, while exactly-once processing ensures that every tuple is processed exactly once, even in the event of failure.
17. Can Apache Storm process batch data?
Answer: While Apache Storm is primarily designed for real-time stream processing, it can process batch data using frameworks like Trident for micro-batch processing.
18. How does Storm compare to Apache Kafka?
Answer: Apache Storm is a stream processing system, whereas Apache Kafka is a distributed message broker used to collect, store, and stream data. Kafka and Storm are often used together, with Kafka as the data source and Storm as the processor.
19. What programming languages does Apache Storm support?
Answer: Apache Storm natively supports Java and can also be integrated with other languages like Python, Ruby, and Scala through multi-language bolts and spouts.
20. What is latency in Apache Storm?
Answer: Latency in Apache Storm refers to the time it takes for a tuple to traverse through the topology from ingestion to completion. Storm is designed for low-latency processing, making it suitable for real-time applications.
21. What is throughput in Apache Storm?
Answer: Throughput refers to the amount of data that can be processed by Storm over a given period. High throughput indicates that the system can process large volumes of data efficiently.
22. How does Apache Storm handle scaling?
Answer: Apache Storm can scale horizontally by adding more worker nodes to the cluster, allowing it to handle larger data streams and more complex topologies.
23. What are worker processes in Storm?
Answer: Worker processes execute components of a Storm topology. Each worker process runs one or more executors, which in turn run the Spouts and Bolts that process the data.
24. How can Storm be integrated with Hadoop?
Answer: Storm can be integrated with Hadoop by writing data from Storm topologies to HDFS for long-term storage or by using Storm to process data streams from Hadoop-based applications in real time.
25. How does Storm manage resource allocation?
Answer: Storm manages resource allocation through its cluster manager, Nimbus. Users can also set the number of worker nodes, executors, and memory resources when submitting topologies to balance the load.
26. What are the use cases for Apache Storm?
Answer: Common use cases include real-time analytics, fraud detection, log processing, social media monitoring, real-time recommendation engines, and IoT (Internet of Things) data processing.
27. What is Storm’s role in IoT applications?
Answer: Apache Storm is ideal for IoT applications because it can process high-velocity streams of sensor data in real time, enabling immediate actions based on the data.
28. What is the future of Apache Storm?
Answer: Apache Storm continues to evolve with new features like enhanced fault tolerance, better integration with other stream processing frameworks, and improved support for machine learning applications.

29. Can Storm be deployed on the cloud?
Answer: Yes, Apache Storm can be deployed on cloud platforms such as AWS, Google Cloud, and Azure. Cloud deployments provide flexibility and scalability for handling large-scale stream processing.
30. How can Storm be monitored?
Answer: Storm provides several monitoring tools, including the Storm UI for visualizing topology performance and metrics, as well as integration with external monitoring systems like Prometheus and Grafana for in-depth monitoring.