DataOps combines DevOps practices and Agile methodologies to streamline data processes, improve data quality, and foster collaboration across teams. When deploying DataOps, following best practices is essential to maximize its impact on data operations. This guide outlines best practices for a successful DataOps deployment that will enhance data quality, agility, and operational efficiency.
1. Prioritize Data Quality and Consistency
- Automate Data Quality Checks: Embed data validation and consistency checks within data pipelines to catch and resolve data issues early.
- Establish Quality Standards: Define and enforce data quality standards across your organization to ensure consistency, reliability, and usability of data.
- Implement Data Governance: Use DataOps to integrate governance policies that maintain data accuracy and align with compliance requirements.
2. Adopt Continuous Integration and Continuous Deployment (CI/CD)
- Set Up CI/CD Pipelines for Data: Adapt CI/CD principles from DevOps to automate data testing, deployment, and delivery.
- Frequent Pipeline Testing: Regularly test data pipelines to detect and address issues early. Automate unit and integration testing to ensure data accuracy.
- Version Control for Data Pipelines: Use version control systems to manage data pipeline changes, enabling teams to roll back to stable versions as needed.
3. Automate Data Pipelines for Efficiency
- End-to-End Pipeline Automation: Use ETL/ELT tools like Apache NiFi, dbt, or Fivetran to automate data workflows from ingestion to transformation.
- Data Transformation Automation: Automate data transformations and data quality checks to ensure reliable, clean data reaches downstream analytics and applications.
- Reduce Manual Interventions: Minimize human involvement in routine data operations, reducing the likelihood of errors and inconsistencies.
4. Foster a Culture of Cross-Functional Collaboration
- Build a Cross-Functional Data Team: Bring together data engineers, scientists, analysts, and business stakeholders to align goals and improve communication.
- Encourage Regular Standups and Retrospectives: Hold Agile-style meetings to review progress, discuss challenges, and iterate on pipeline improvements.
- Promote Transparency: Use shared dashboards and reporting tools to keep all stakeholders informed and aligned on the current status of data operations.
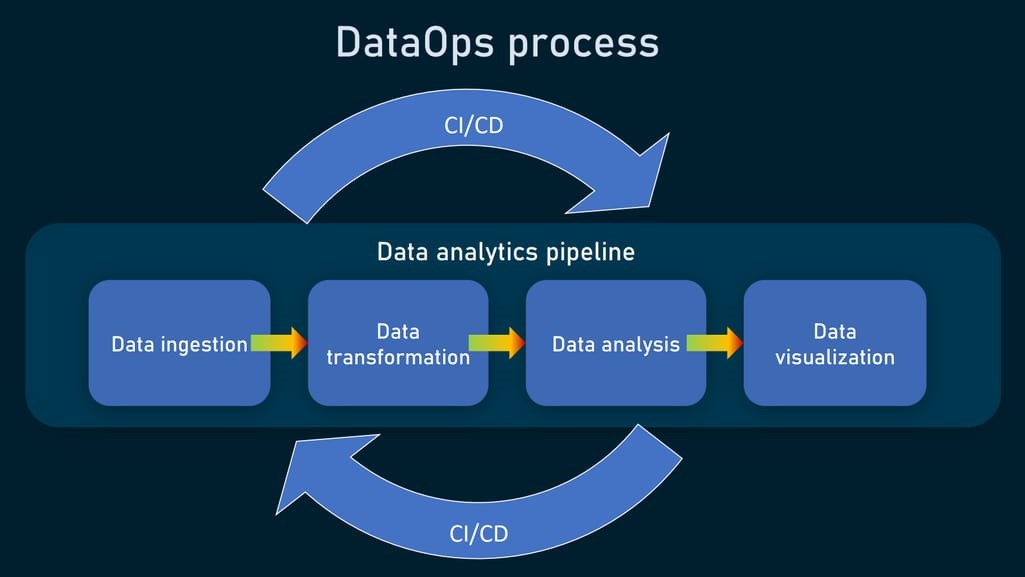
5. Implement Real-Time Monitoring and Alerting
- Set Up End-to-End Monitoring: Use monitoring tools like Grafana, Prometheus, or DataDog to monitor data flows, pipeline health, and data freshness in real-time.
- Configure Automated Alerts: Automate alerts to notify teams of data quality issues, pipeline errors, or performance bottlenecks for quick resolution.
- Establish a Feedback Loop: Use monitoring data and user feedback to continuously improve data pipelines and address recurring issues.
6. Emphasize Data Security and Compliance
- Implement Role-Based Access Control (RBAC): Use RBAC to restrict access to sensitive data, ensuring only authorized personnel have access based on their roles.
- Automate Compliance Checks: Integrate compliance and privacy policies (e.g., GDPR, HIPAA) directly into your DataOps workflows to protect sensitive data.
- Ensure Data Privacy: Use encryption, data masking, and anonymization techniques to maintain data privacy and security throughout the data lifecycle.
7. Embrace Agile and Iterative Development
- Adopt Agile Methodologies: Use sprints and iterative cycles to develop, test, and deploy data pipelines, allowing for continuous improvement and adaptation.
- Incorporate Feedback Loops: Continuously gather feedback from data users to identify pain points, refine data workflows, and make necessary adjustments.
- Maintain Flexibility: Keep pipelines adaptable to new data sources, changes in compliance requirements, or shifting business needs.
8. Leverage the Right DataOps Tools
- ETL/Orchestration Tools: Use tools like Apache Airflow, dbt, and Kafka to manage and automate data flows, transformations, and orchestration.
- Monitoring and Alerting Solutions: Implement tools like ELK Stack (Elasticsearch, Logstash, Kibana), Grafana, and Prometheus for pipeline monitoring and error alerts.
- Version Control and Collaboration Platforms: Platforms like GitHub and GitLab enable version control and collaboration, essential for DataOps teams working across locations.
9. Establish Clear Documentation and Versioning
- Document Data Pipelines and Processes: Ensure data workflows, transformations, and configurations are documented to aid troubleshooting, onboarding, and compliance.
- Use Versioned Documentation: Keep documentation updated and versioned alongside data pipelines, ensuring that all changes and configurations are tracked.
10. Scale DataOps as Data Needs Grow
- Build for Scalability: Design data pipelines with scalability in mind to handle increasing data volumes and complexity as your organization grows.
- Automate Scaling for Efficiency: Use cloud-based resources to automatically scale data processing capacity up or down based on data workload demands.
- Optimize Data Storage and Processing: Regularly review data storage and processing strategies to minimize costs while maximizing data accessibility and performance.