DataOps, the combination of data engineering and DevOps practices, is revolutionizing the way organizations handle data. By automating data pipelines, improving collaboration, and accelerating data delivery, DataOps empowers businesses to make data-driven decisions faster.
Core Principles of DataOps
- Continuous Integration and Continuous Delivery (CI/CD) for Data:
- Automate data pipelines to ensure consistent and reliable data flows.
- Implement version control for data pipelines and scripts.
- Use CI/CD tools to automate testing, deployment, and monitoring.
- Collaboration and Communication:
- Foster collaboration between data engineers, data scientists, and business analysts.
- Use effective communication tools and methodologies.
- Establish clear ownership and accountability for data pipelines.
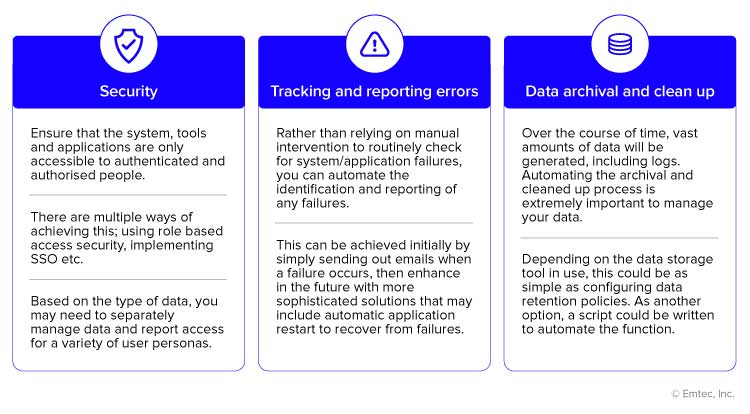
- Data Quality and Monitoring:
- Implement data quality checks and monitoring.
- Use data profiling and data lineage tools.
- Set up alerts for data anomalies and failures.
- Self-Service Data:
- Empower business users to access and analyze data independently.
- Provide user-friendly data exploration and visualization tools.
- Implement data catalog and metadata management.

Best Practices for Implementing DataOps
- Start Small and Iterate:
- Begin with a small, well-defined data pipeline.
- Gradually expand the scope as you gain experience.
- Iterate on your processes and tools to continuously improve.
- Automate Everything:
- Automate data ingestion, transformation, and loading processes.
- Use automation tools to reduce manual effort and human error.
- Implement CI/CD pipelines for data pipelines.
- Prioritize Data Quality:
- Establish data quality standards and metrics.
- Implement data validation and cleansing processes.
- Monitor data quality and take corrective action.
- Leverage Data Lineage:
- Track the origin and transformation of data.
- Understand the impact of data changes on downstream systems.
- Identify potential data quality issues and root causes.
- Collaborate Effectively:
- Foster a culture of collaboration between data teams.
- Use effective communication tools and methodologies.
- Establish clear ownership and accountability for data pipelines.
- Implement Robust Monitoring and Alerting:
- Monitor data pipelines for performance and errors.
- Set up alerts for critical issues.
- Use monitoring tools to track key metrics.
- Embrace Cloud-Native Technologies:
- Leverage cloud-native technologies like Kubernetes and containerization to improve scalability and flexibility.
- Use cloud-based data warehouses and data lakes.
- Leverage DataOps Tools and Technologies:
- Use tools like dbt, Apache Airflow, and Luigi to automate data pipelines.
- Use data catalog and metadata management tools to organize and manage data.
- Use data quality tools to monitor and improve data quality.
Key Benefits of DataOps
- Increased Data Velocity: Faster data delivery and time to insights.
- Improved Data Quality: Higher data accuracy and reliability.
- Enhanced Collaboration: Better collaboration between data teams.
- Reduced Time to Market: Faster deployment of data products.
- Increased Innovation: Empowers data scientists and analysts to focus on innovation.