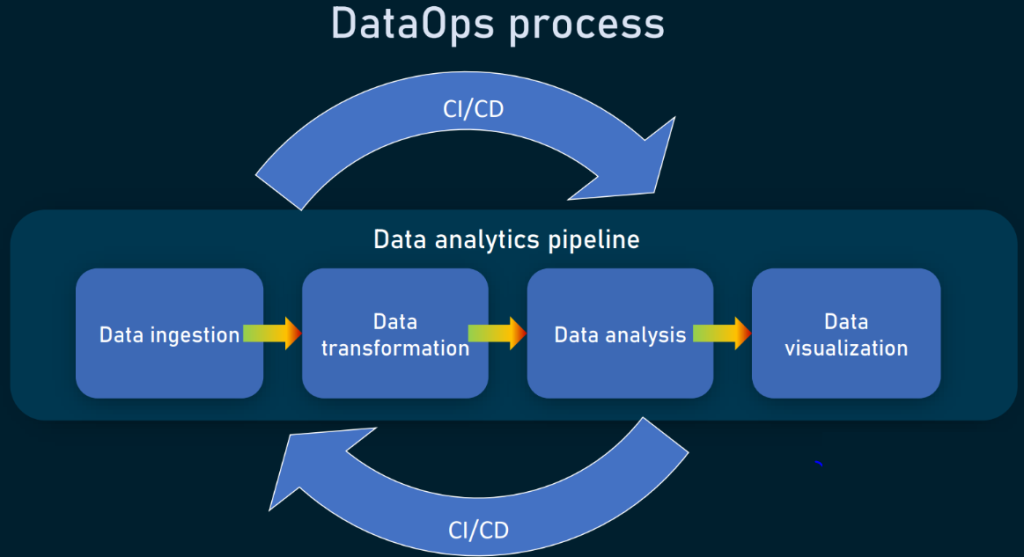
Implementing DataOps in an organization can be a complex and challenging process, but it can be broken down into several key steps:
Define the problem or opportunity:
Identify the specific business problem or opportunity that DataOps is intended to address.
Build a cross-functional team:
Assemble a team of individuals from different functional areas of the organization, such as data engineers, data scientists, data analysts, and IT operations personnel.
Establish clear roles and responsibilities:
Define the roles and responsibilities of each team member and ensure that everyone understands their part in the process.
Develop a data governance and security plan:
Create a plan for data governance, security and compliance, including policies, procedures and roles for managing and controlling access to data.
Define metrics for success:
Identify the metrics that will be used to measure the success of the DataOps initiative, such as increased efficiency, improved data quality and reduced time to market.
Create a feedback loop:
Establish a system for regularly collecting and analyzing feedback from team members and stakeholders, and use that feedback to make adjustments and improvements to the DataOps process.
Automate and standardize:
Automate and standardize data pipeline, testing, validation, and monitoring to improve the speed and reliability of data-driven decisions.
Continuous improvement:
Continuously review and improve the process by regularly assessing the outcome, and making changes as necessary.
Foster a culture of collaboration and transparency:
Encourage an environment where team members feel comfortable sharing ideas and feedback, and where information is easily accessible to all stakeholders.
It’s important to note that the implementation of DataOps requires a change in culture and mindset, it’s not only a one-time implementation but a continuous effort to establish efficient, accurate, and secure