DataOps is a cultural and technical movement that aims to increase the speed and quality of data delivery. By combining DevOps practices with data engineering, DataOps enables organizations to automate data pipelines, improve collaboration, and reduce time to market.
Here’s a step-by-step guide to implementing DataOps in your organization:
1. Define Your DataOps Goals
- Identify key pain points: Determine the specific challenges your organization faces in data delivery.
- Set clear objectives: Define what you want to achieve with DataOps, such as faster time to insights, improved data quality, or increased data accessibility.
- Establish a DataOps team: Assemble a cross-functional team of data engineers, data scientists, and business analysts.
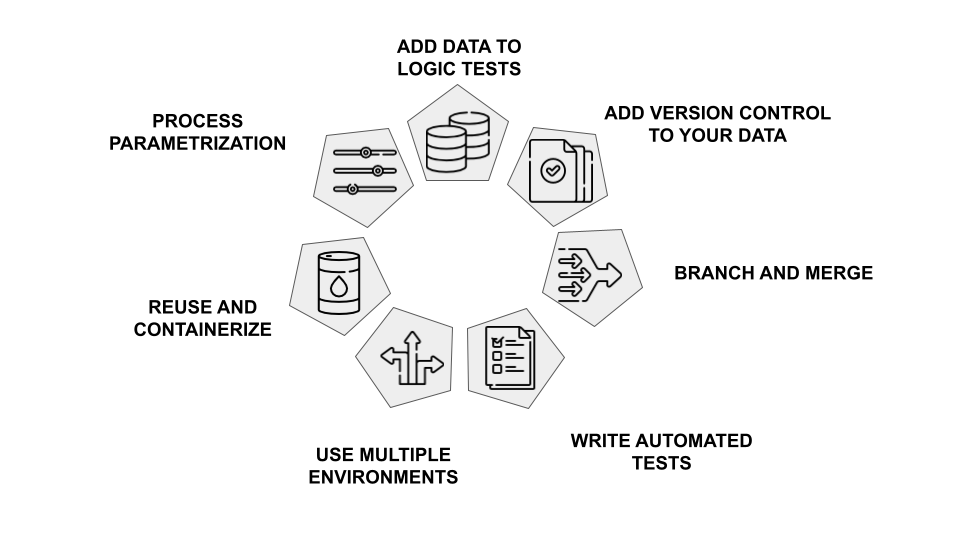
2. Choose the Right Tools and Technologies
- Data Orchestration: Select a tool like Apache Airflow, Luigi, or dbt to automate data pipelines.
- Data Integration: Choose tools like Talend, Informatica, or Fivetran for data ingestion and transformation.
- Data Warehousing and Data Lakes: Select a data warehouse or data lake solution like Snowflake, Databricks, or Amazon Redshift.
- Data Quality: Use tools like Great Expectations or Data Quality to monitor and improve data quality.
- CI/CD: Implement CI/CD pipelines with tools like Jenkins, GitLab CI/CD, or CircleCI.
3. Establish Data Governance and Standards
- Data Governance: Define data ownership, data quality standards, and data security policies.
- Data Catalog: Create a data catalog to document data assets and their metadata.
- Data Lineage: Track the origin and transformation of data to improve data understanding and troubleshooting.
4. Implement Data Pipelines
- Design data pipelines: Break down complex data pipelines into smaller, modular components.
- Automate data ingestion: Set up automated data ingestion processes from various sources.
- Transform and clean data: Use data transformation tools to clean, enrich, and transform data.
- Load data into the target system: Load transformed data into data warehouses, data marts, or data lakes.
5. Monitor and Optimize
- Implement monitoring: Use tools like Prometheus and Grafana to monitor data pipeline performance.
- Set up alerts: Define alerts for failures, anomalies, and performance degradation.
- Optimize data pipelines: Continuously optimize data pipelines for performance and efficiency.
6. Foster a Data-Driven Culture
- Data Literacy: Educate employees on data concepts and tools.
- Self-Service Analytics: Empower business users to access and analyze data independently.
- Data-Driven Decision Making: Encourage data-driven decision-making at all levels of the organization.
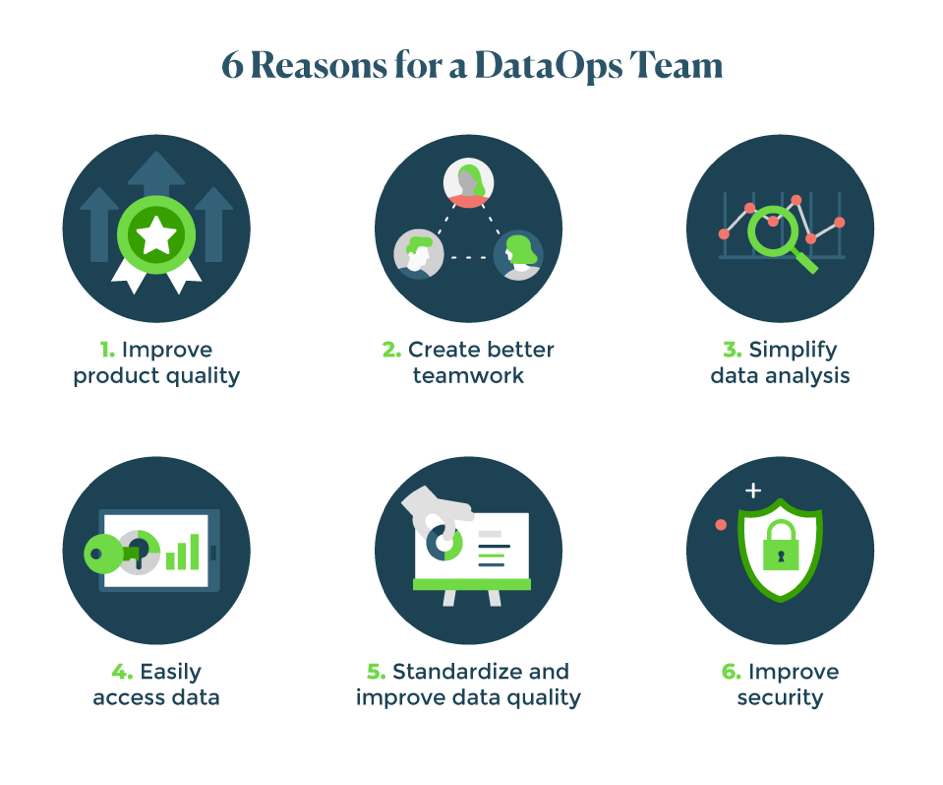
Key Challenges and Considerations
- Data Quality: Ensure data quality throughout the data pipeline.
- Data Security and Privacy: Implement robust security measures to protect sensitive data.
- Scalability: Design data pipelines to handle increasing data volumes and complexity.
- Change Management: Manage change effectively and communicate with stakeholders.
- Tool Selection: Choose the right tools and technologies for your specific needs.