In today’s data-driven environment, organizations rely heavily on efficient data pipelines to process, clean, and transform data for analytics and decision-making. However, data pipelines often face challenges like data quality issues, delays, and operational inefficiencies. DataOps, a methodology that applies DevOps principles to data engineering, has emerged as a powerful way to optimize data pipelines. In this blog, we explore how DataOps enhances data pipeline performance and provides a robust foundation for scalable data operations.
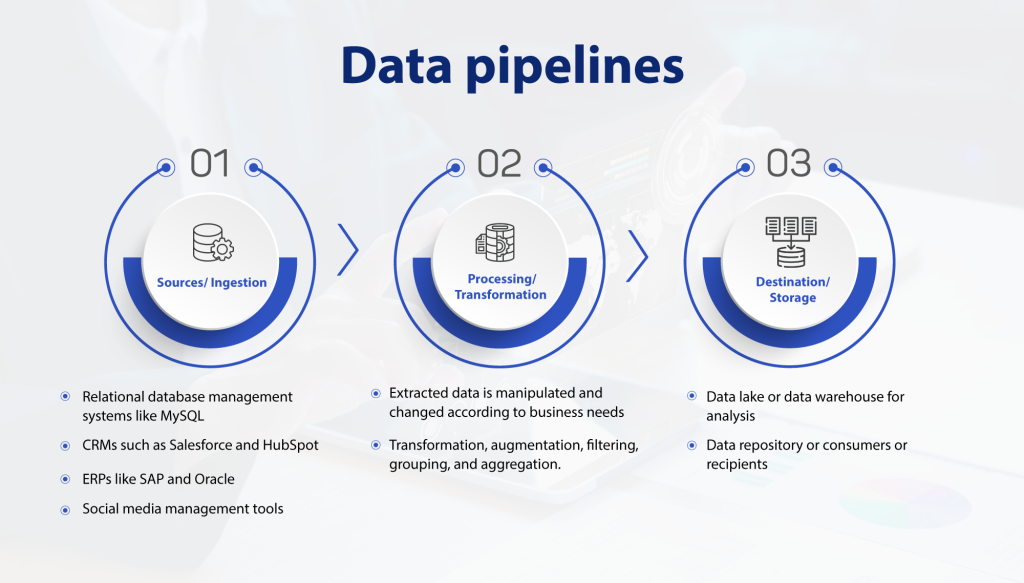
1. Automating Data Pipeline Workflows
- Automated Orchestration: DataOps tools allow for automated orchestration of data flows, reducing manual intervention and streamlining pipeline processes.
- End-to-End Automation: From data ingestion to cleaning, transformation, and delivery, automation minimizes the potential for human error and ensures smooth, uninterrupted data movement.
- Data Pipeline Scheduling: With scheduling features, DataOps platforms help trigger data pipelines at specific intervals or in response to specific events, improving the timeliness of data delivery.
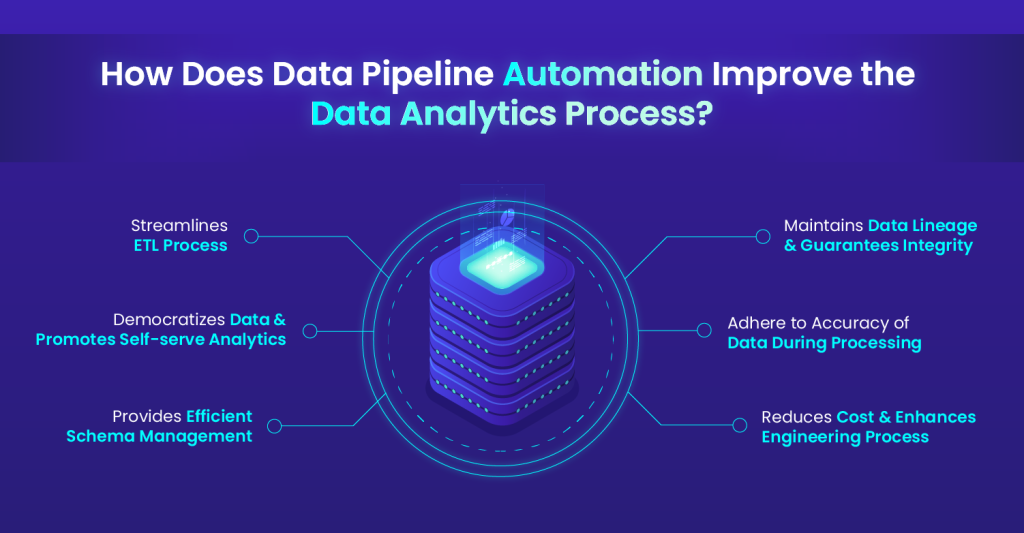
2. Enhancing Data Quality with Continuous Testing
- Data Validation and Testing: DataOps introduces continuous testing mechanisms that validate data at each stage of the pipeline, ensuring accuracy and reliability.
- Error Detection and Resolution: Automated data quality checks catch anomalies early, allowing data teams to fix errors before they propagate through the pipeline.
- Data Quality Metrics: By measuring data quality metrics (e.g., accuracy, completeness), DataOps tools help teams maintain high standards for the data being processed.
3. Implementing Agile Data Management Practices
- Iterative Development: DataOps promotes iterative development in data engineering, allowing teams to release incremental updates to pipelines, enhancing agility and adaptability.
- Improving Responsiveness: Agile practices enable data teams to respond quickly to changing data needs or business requirements without disrupting ongoing operations.
- Reducing Development Cycle Time: By applying Agile principles, DataOps shortens development cycles, accelerating the delivery of updated data pipelines.
4. Reducing Pipeline Downtime through Monitoring and Alerting
- Proactive Monitoring: DataOps platforms continuously monitor pipeline health and performance, providing visibility into potential issues before they escalate.
- Real-Time Alerts: With real-time alerting, teams are instantly notified of any pipeline disruptions, minimizing downtime and ensuring timely data delivery.
- Historical Pipeline Performance Data: Monitoring tools track historical performance, allowing teams to identify bottlenecks and optimize pipeline configurations.
5. Enabling Collaboration Across Data Teams
- Centralized Data Management: DataOps tools provide a unified platform for data engineers, analysts, and stakeholders, fostering a collaborative environment.
- Improved Transparency: By enabling visibility into each stage of the pipeline, DataOps allows team members to better understand data flows, dependencies, and potential risks.
- Version Control for Data Pipelines: Like in DevOps, version control enables teams to track changes in pipeline configurations and roll back to previous versions if needed.
6. Scaling Data Pipelines Efficiently
- Elastic Scalability: DataOps tools can automatically scale resources based on data volume, ensuring that pipelines handle spikes in data without performance degradation.
- Resource Optimization: By automating resource allocation, DataOps optimizes costs while maintaining high performance across data workflows.
- Supporting Big Data Workloads: Many DataOps platforms are designed to handle high-volume, high-velocity data, making them ideal for big data applications.