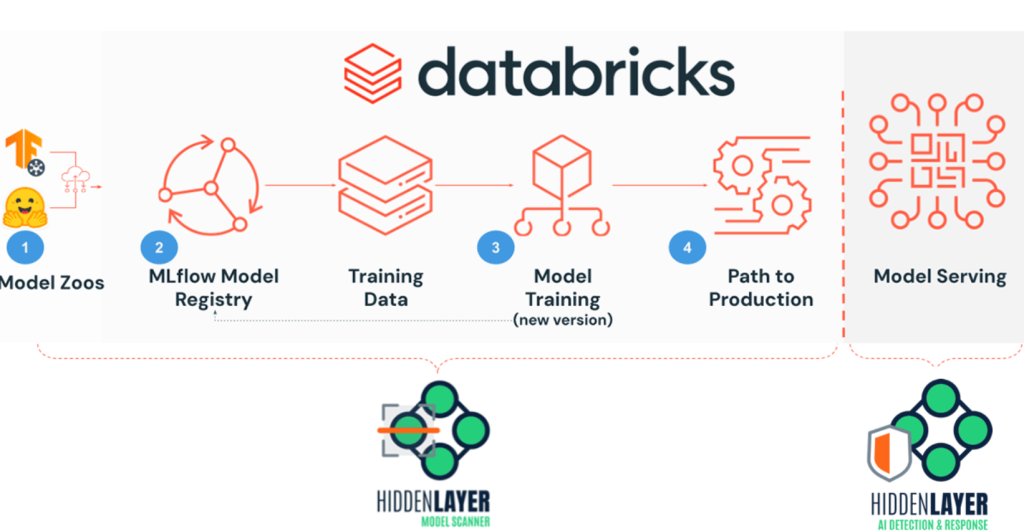
Databricks is a cloud-based platform that combines data engineering, data science, machine learning, and analytics into a unified platform. It is built on Apache Spark, an open-source distributed computing framework, and offers a collaborative environment for working with large-scale data and building data-driven applications.
Key Features of Databricks:
- Unified Analytics Platform: Combines ETL (Extract, Transform, Load), data exploration, and machine learning workflows in one place.
- Apache Spark Integration: Seamlessly integrates with Spark for processing large-scale data quickly.
- Collaboration: Enables teams to work together using notebooks, which support multiple programming languages like Python, SQL, R, and Scala.
- Scalability: Dynamically scales resources to handle data workloads of any size.
- Machine Learning: Simplifies the end-to-end machine learning lifecycle, from data preparation to model training and deployment.
- Data Lakehouse Architecture: Combines the benefits of data lakes (storage) and data warehouses (structured query performance) into a single platform.
- Delta Lake: Provides robust data storage with ACID transactions, ensuring data consistency and reliability.
- Integration with Cloud Providers: Supports deployment on major cloud platforms like AWS, Microsoft Azure, and Google Cloud.
Common Use Cases:
- Data Engineering: Building ETL pipelines to process and transform raw data.
- Data Science: Developing and testing predictive models.
- Machine Learning: Training, deploying, and monitoring machine learning models.
- Real-Time Analytics: Processing and analyzing streaming data in real-time.
- Business Intelligence: Querying structured data for reporting and insights.
Benefits:
- Collaboration: Provides shared workspaces for teams.
- Productivity: Simplifies the process of building data pipelines and machine learning workflows.
- Performance: Accelerates data processing with Apache Spark.
- Cost Efficiency: Optimizes costs with scalable cloud resources.
Best Databricks Alternatives
There are several platforms similar to Databricks that provide capabilities for data engineering, data science, machine learning, and analytics. These platforms often focus on processing large-scale data, offering collaborative environments, and integrating with cloud services. Here’s a detailed list of Databricks alternatives:
1. Apache Spark
- Description: Open-source distributed data processing framework, which Databricks is built upon.
- Features:
- Supports batch and real-time data processing.
- Offers APIs in Python, Java, Scala, and R.
- Requires self-management for setup, cluster management, and optimization.
- When to Use: If you want full control over your Spark environment and have the expertise to manage it.
- Notable Difference: Databricks provides an optimized Spark runtime and additional features like Delta Lake, collaborative notebooks, and MLflow.
2. Amazon EMR (Elastic MapReduce)
- Description: Managed cluster platform on AWS for big data processing.
- Features:
- Supports frameworks like Spark, Hadoop, Presto, and Hive.
- Seamless integration with AWS services like S3, Redshift, and DynamoDB.
- Auto-scaling and cost-effective spot instance options.
- When to Use: For AWS users needing flexible big data frameworks and integration with the AWS ecosystem.
3. Google Cloud Dataproc
- Description: Fully managed Spark and Hadoop service on Google Cloud.
- Features:
- Runs Apache Spark and Hadoop clusters.
- Tight integration with GCP services like BigQuery, Cloud Storage, and AI tools.
- Pay-per-second pricing for cost efficiency.
- When to Use: For Google Cloud users who prefer managed Spark and Hadoop services.
4. Azure Synapse Analytics
- Description: A data integration and analytics service on Microsoft Azure.
- Features:
- Unified platform for data warehousing, big data, and analytics.
- Integrates with Azure Data Lake, Power BI, and other Azure services.
- Offers both serverless and provisioned compute options.
- When to Use: For Azure users focusing on enterprise analytics and data integration.
5. Snowflake
- Description: Cloud-based data warehousing platform with built-in analytics capabilities.
- Features:
- Supports structured and semi-structured data.
- Elastic compute and storage scalability.
- Provides SQL-based data processing.
- When to Use: For use cases focused on data warehousing and SQL analytics.
6. Cloudera Data Platform (CDP)
- Description: Enterprise data platform for big data analytics and machine learning.
- Features:
- Supports Hadoop, Spark, and other frameworks.
- Offers hybrid and multi-cloud deployment options.
- Includes data governance and security tools.
- When to Use: For enterprises requiring a comprehensive solution for big data management and compliance.
7. IBM Watson Studio
- Description: Collaborative environment for data science, machine learning, and AI.
- Features:
- Tools for data preparation, model building, and deployment.
- Built-in AutoAI for automated model building.
- Integration with IBM Cloud and on-premise options.
- When to Use: For organizations focused on AI and advanced analytics.
8. Hadoop
- Description: Open-source framework for distributed storage and processing of large datasets.
- Features:
- Consists of HDFS (storage), MapReduce (processing), and YARN (resource management).
- Can run on commodity hardware.
- When to Use: For businesses needing an open-source solution for big data management.
9. Microsoft Azure Databricks
- Description: A version of Databricks integrated into Microsoft Azure.
- Features:
- Built on Apache Spark.
- Optimized for Azure services like Data Lake and Synapse Analytics.
- When to Use: Ideal for Azure users who want Databricks’ capabilities with native Azure integration.
10. AWS Glue
- Description: Serverless data integration service by AWS.
- Features:
- Extract, transform, and load (ETL) service.
- Supports PySpark for data processing.
- Works with data in S3, Redshift, and RDS.
- When to Use: For simple ETL workflows in the AWS ecosystem.
11. Dask
- Description: Open-source parallel computing library in Python.
- Features:
- Provides tools for distributed data processing.
- Integrates seamlessly with Python libraries like Pandas and NumPy.
- When to Use: For Python developers requiring lightweight distributed data processing.
12. KNIME Analytics Platform
- Description: Open-source platform for data analytics and machine learning.
- Features:
- Visual workflow designer for ETL and data science.
- No-code/low-code interface.
- Supports integration with Python, R, and Spark.
- When to Use: For users who prefer visual programming for data workflows.
13. Alteryx
- Description: Analytics automation platform for data preparation and advanced analytics.
- Features:
- Drag-and-drop interface for ETL and analytics workflows.
- Built-in tools for predictive modeling and machine learning.
- When to Use: For business analysts and data teams requiring no-code automation tools.
14. Qubole
- Description: Cloud-native big data platform for data engineering and machine learning.
- Features:
- Supports Spark, Hive, Presto, and TensorFlow.
- Offers auto-scaling clusters and multi-cloud support.
- When to Use: For organizations focusing on big data analytics across cloud platforms.
15. Zeppelin
- Description: Open-source web-based notebook for data analytics.
- Features:
- Interactive notebooks for Apache Spark.
- Multi-language support (Python, Scala, SQL, etc.).
- When to Use: As an open-source alternative to Databricks Notebooks.
Would you like a comparison of these platforms or assistance selecting the best one for your needs?
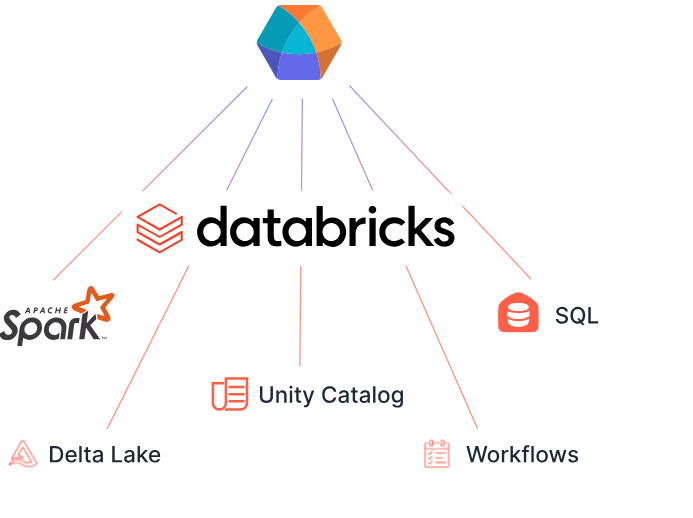
Core Components
- Workspace: A centralized environment for team collaboration.
- Notebooks: Interactive documents for code execution, similar to Jupyter notebooks.
- Apache Spark: The underlying engine for big data processing.
- Delta Lake: An open-source storage layer that enhances data reliability.
- Unity Catalog: A system for centralized metadata management and governance
Cloud Integration
Databricks integrates with major cloud providers, including Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform. This allows organizations to leverage their existing cloud infrastructure while using Databricks’ capabilities.In summary, Databricks offers a comprehensive platform for modern data analytics and AI, enabling organizations to unify their data processes, collaborate effectively, and derive valuable insights from their data assets.
Great! Let me dive deeper into the key aspects of Databricks. Let me know which one you’d like to explore further or if you want a full breakdown:
1. Unified Analytics Platform
Databricks integrates the entire data lifecycle in one place:
- Data Engineering: Simplify and automate ETL pipelines to process large volumes of data.
- Data Science: Collaborative notebooks allow data scientists to experiment and visualize results quickly.
- Analytics: SQL support lets analysts run queries directly on the data lake.
- Machine Learning: End-to-end support for model building, training, and deployment.
Example:
A retail company could use Databricks to:
- Collect data from online stores (data engineering).
- Analyze customer purchase trends (analytics).
- Build models to predict future demand (machine learning).
2. Apache Spark Integration
Databricks is built on Apache Spark, which is renowned for its:
- Distributed computing: Efficiently processes large datasets across clusters.
- Multi-language support: Python, Scala, Java, R, and SQL.
- Libraries for structured data processing, streaming, and machine learning.
Why Spark Matters:
- Speeds up batch processing and real-time analytics.
- Handles petabyte-scale data with ease.
3. Collaboration and Notebooks
Databricks supports interactive, multi-language notebooks where teams can:
- Write code in Python, R, Scala, and SQL in a single notebook.
- Share workspaces for real-time collaboration.
- Visualize results with built-in charting tools.
Example Use:
- A team analyzing customer data can work together in a shared notebook, with data engineers setting up pipelines, data scientists building predictive models, and analysts visualizing insights—all in the same environment.
4. Data Lakehouse Architecture
The Databricks Lakehouse combines the best of both:
- Data Lakes: Store raw, unstructured, and semi-structured data.
- Data Warehouses: Query and analyze structured data with high performance.
Advantages:
- Cost Savings: A single system avoids duplication of storage and processing.
- Flexibility: Supports both big data workloads and traditional BI queries.
5. Delta Lake
Delta Lake is a core feature that enhances data lakes with:
- ACID Transactions: Ensures data consistency.
- Schema Enforcement: Prevents schema mismatches during data writes.
- Time Travel: Query historical data as it appeared at a specific time.
Use Case:
In a financial application, Delta Lake ensures:
- Data reliability for regulatory reporting.
- The ability to audit changes to datasets.
6. Machine Learning
Databricks simplifies the machine learning lifecycle:
- Feature Store: Centralized storage for reusable features.
- MLflow Integration: Tracks experiments, manages models, and automates deployment.
- Hyperparameter Tuning: Automated search for optimal parameters.
Example:
A healthcare provider could build ML models to:
- Predict patient outcomes.
- Deploy the model to monitor live patient data for anomalies.
7. Real-Time Analytics
Supports streaming data with tools like Spark Streaming and Delta Live Tables. This is crucial for:
- Fraud Detection: Analyze transactions in real-time.
- IoT Applications: Process sensor data instantly.
Example:
A logistics company can:
- Monitor real-time GPS data from trucks.
- Adjust delivery routes dynamically to improve efficiency.
8. Integration with Cloud Providers
Databricks runs seamlessly on:
- AWS: Uses S3 for storage and integrates with AWS analytics services.
- Azure: Tight integration with Azure services like Azure Data Factory and Azure Synapse Analytics.
- Google Cloud: Works with BigQuery and GCP-native tools.
Benefits:
- Scalability: Dynamically allocate resources.
- Cost Optimization: Pay only for what you use.
Would you like to go deeper into:
- Hands-on examples?
- Pricing and setup on a specific cloud?
- Tutorials for building pipelines or ML models?
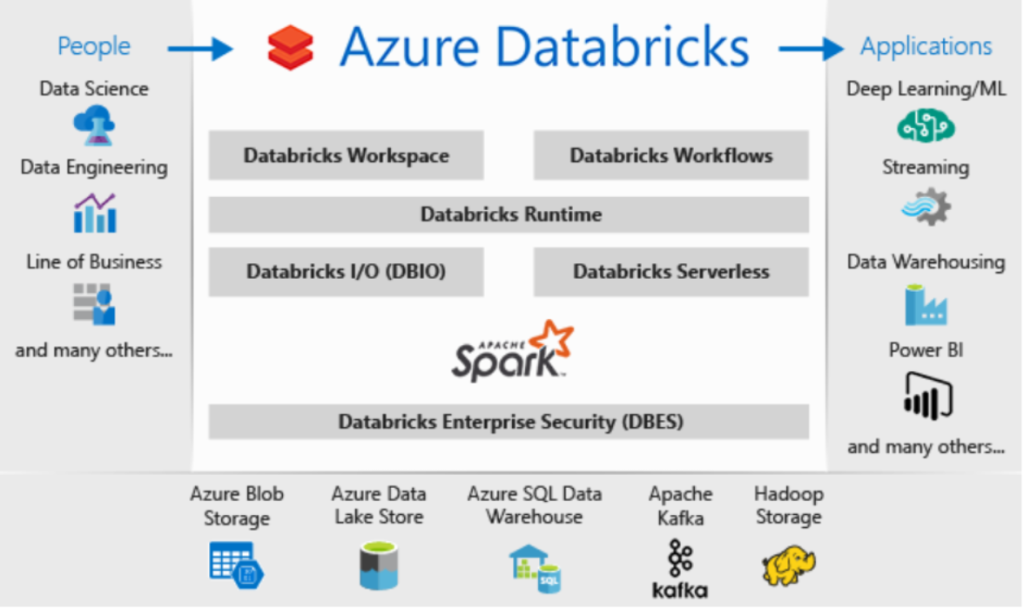
Databricks Architecture
Databricks is built on a robust and scalable architecture designed to handle diverse workloads in a unified environment. Its architecture is built on Apache Spark and integrates seamlessly with cloud storage and compute environments. Here’s an overview of the key components of the Databricks architecture:
1. Core Layers in Databricks Architecture
A. Cloud Infrastructure Layer
- Databricks operates on major cloud platforms: AWS, Azure, and Google Cloud.
- Relies on cloud storage for data (e.g., S3, Azure Blob Storage, Google Cloud Storage).
- Leverages cloud compute resources for processing (e.g., EC2, Azure VMs, GCP VMs).
B. Databricks Runtime
- A customized Apache Spark-based engine optimized for performance and reliability.
- Includes additional libraries for:
- Delta Lake: Provides ACID transactions, schema enforcement, and time travel.
- MLlib: For machine learning tasks.
- GraphX: For graph processing.
C. Databricks Workspace
A collaborative environment for data teams, providing:
- Notebooks: Interactive, multi-language notebooks for coding and visualizations.
- Dashboards: For sharing data insights and reports.
- Job Scheduler: Automates ETL and other workflows.
D. Data Layer
Handles storage and processing of data:
- Delta Lake:
- Enhances data lakes with ACID transactions.
- Supports batch and streaming workloads.
- Data Lakes:
- Raw data storage (e.g., S3, Blob Storage).
- Data Warehouses:
- Query-optimized storage for analytics.
E. Compute Management Layer
- Clusters: Managed clusters for running Spark jobs.
- Automatically scaled based on workload.
- Optimized for cost and performance.
- Job Clusters: Temporary clusters for short-lived jobs.
- Interactive Clusters: Persistent clusters for collaborative work.
2. Key Components in the Databricks Architecture
A. Control Plane
- Hosted by Databricks (managed service).
- Handles the management and orchestration of resources, including:
- User authentication and authorization.
- Monitoring and logging.
- Notebooks and job scheduling.
- Does not access your data directly for security.
B. Data Plane
- Runs in the user’s cloud account.
- Processes data and stores it in your cloud storage.
- Provides data isolation for security and compliance.
3. Workflow in Databricks
- Data Ingestion:
- Data is ingested into the platform from multiple sources (e.g., APIs, databases, IoT).
- Supports batch and real-time streaming data.
- Data Storage:
- Raw data is stored in a data lake or Delta Lake for processing.
- Data Processing:
- Leveraging Spark, data is transformed for analytics or machine learning.
- Data pipelines are created using SQL, Python, Scala, or R.
- Machine Learning and Analytics:
- Machine learning models are built and trained using the Databricks Runtime for ML.
- Analytical insights are generated and visualized in notebooks.
- Deployment:
- Models and ETL pipelines are deployed to production using MLflow or APIs.
4. Benefits of Databricks Architecture
- Scalability:
- Dynamically scales compute resources to meet workload demands.
- Collaboration:
- Unified workspace supports cross-functional teams.
- Cost Efficiency:
- Clusters automatically shut down when not in use.
- Optimized for both batch and streaming workloads.
- Performance:
- Built-in optimizations to Spark and integration with Delta Lake for fast queries.
- Security:
- Data isolation with the separation of control and data planes.
- Integration with cloud-native security tools.
High-Level Architecture Diagram
Here’s a simplified breakdown:
USER LAYER
- Notebooks
- Dashboards
- APIs (REST/SDKs)
CONTROL PLANE
- User Management
- Cluster Management
- Monitoring
- Job Scheduling
DATA PLANE (Cloud Account)
- Compute Resources (Clusters)
- Storage (Delta Lake, Data Lake)
- Spark Engine
Databricks Terminology
Understanding the key terms and concepts in Databricks is essential for efficiently navigating the platform. Here’s a list of important Databricks terminology:
General Concepts
- Workspace
- The primary interface for Databricks users.
- A collaborative environment for managing data, running jobs, and sharing notebooks.
- Organizes assets like notebooks, libraries, and datasets.
- Notebook
- An interactive document that allows users to write code, visualize data, and share results.
- Supports multiple languages (Python, SQL, R, Scala) and markdown for documentation.
- Dashboard
- A visual interface to present key insights and visualizations.
- Can be shared for business reporting.
- Cluster
- A group of virtual machines that Databricks uses to run computations.
- Types of clusters:
- Interactive Clusters: Persistent, used for collaborative work.
- Job Clusters: Temporary, created for running specific jobs.
- Job
- A task or set of tasks scheduled to run on a cluster.
- Often used for ETL pipelines, data processing, or model training.
- Library
- External packages or dependencies that can be installed on Databricks clusters.
- Examples: PyPI (Python libraries), Maven (Java/Scala libraries).
Data Management
- Delta Lake
- An open-source storage layer on top of data lakes.
- Provides ACID transactions, schema enforcement, and time travel for data versioning.
- Data Lakehouse
- Combines the scalability of data lakes with the performance and query efficiency of data warehouses.
- DBFS (Databricks File System)
- A distributed file system that abstracts cloud storage (e.g., S3, Azure Blob).
- Allows users to access and store data directly in Databricks.
- Table
- A structured representation of data in Databricks.
- Types:
- Managed Table: Databricks manages both metadata and data.
- Unmanaged Table: Databricks manages metadata, but data remains in external storage.
- Parquet
- A columnar storage format used in Databricks for efficient querying and storage.
Programming and Workflows
- Databricks Runtime (DBR)
- An optimized version of Apache Spark with built-in libraries for machine learning, streaming, and data processing.
- MLflow
- An open-source framework integrated with Databricks for managing the entire machine learning lifecycle, including:
- Experiment tracking
- Model management
- Deployment
- An open-source framework integrated with Databricks for managing the entire machine learning lifecycle, including:
- Spark SQL
- A module for running SQL queries on structured data in Databricks.
- Structured Streaming
- A framework for real-time data streaming within Databricks.
- Widgets
- UI elements in notebooks that allow users to add input parameters (e.g., dropdowns, text boxes).
Security and Administration
- Access Control Lists (ACLs)
- Rules that define permissions for accessing workspaces, clusters, and data.
- Secret Scope
- A secure storage location for managing sensitive information like API keys and passwords.
- Token
- An authentication method to access the Databricks REST API.
- Data Plane and Control Plane
- Control Plane: Managed by Databricks, handles orchestration, and user interface.
- Data Plane: Runs in the user’s cloud account and handles data processing.
Integration and APIs
- REST API
- Enables programmatic interaction with Databricks to manage clusters, jobs, and resources.
- Databricks Connect
- Allows local development of Spark jobs that can be run on Databricks clusters.
- Unity Catalog
- A unified data governance solution for managing access to data across Databricks.
- Delta Sharing
- A protocol for securely sharing Delta Lake tables with external clients.
User Roles
- Admin
- A user with permissions to manage the Databricks workspace, clusters, and users.
- Data Engineer
- Focuses on creating and managing ETL pipelines and transforming raw data.
- Data Scientist
- Uses Databricks for exploratory data analysis and machine learning model development.
- Analyst
- Queries structured data using SQL and creates dashboards for reporting.
Would you like detailed explanations or examples of any of these terms?
How to Get Started with Databricks
Getting started with Databricks involves setting up an account, configuring the environment, and understanding how to use the platform effectively. Here’s a step-by-step guide:
1. Choose a Cloud Provider
Databricks is available on AWS, Microsoft Azure, and Google Cloud Platform (GCP).
- Choose the platform where your organization’s data and resources are hosted.
- If you’re exploring Databricks for personal use, start with the free trial on your preferred cloud provider.
2. Set Up Databricks
A. Create a Databricks Account
- Visit the Databricks website or your cloud provider’s marketplace.
- AWS: Databricks on AWS
- Azure: Databricks on Azure
- GCP: Databricks on GCP
- Sign up for a free trial or log in with your existing cloud account.
B. Deploy Databricks Workspace
- Follow the setup guide for your cloud provider:
- AWS: Use the Databricks Quickstart template to launch a workspace.
- Azure: Use the Azure Portal to deploy a Databricks Service.
- GCP: Set up through the Google Cloud Console.
- Configure:
- Virtual Private Cloud (VPC) settings.
- IAM roles and permissions.
- Networking (subnets, security groups).
3. Understand Databricks Workspace
Once the workspace is set up, familiarize yourself with its components:
- Home: Access your notebooks, libraries, and data.
- Clusters: Manage computing resources for running jobs and notebooks.
- Jobs: Automate and schedule workflows.
- Data: View and manage datasets.
- Notebooks: Create interactive documents for code and analysis.
4. Create a Cluster
Clusters are the computational backbone of Databricks.
Steps:
- Navigate to the Clusters tab.
- Click Create Cluster.
- Provide a name for the cluster.
- Choose the Databricks Runtime version (e.g.,
10.x). - Select the instance types (e.g.,
Standard_DS3_v2for Azure,m5.largefor AWS). - Set auto-scaling options and termination policies.
- Click Create.
5. Load Data into Databricks
A. Upload Local Data
- Go to the Data tab in the workspace.
- Click Add Data > Upload File.
- Select a file from your local machine (e.g., CSV, JSON, or Parquet).
B. Connect to External Data Sources
- Connect to cloud storage:
- AWS S3: Use IAM roles or keys to access your S3 bucket.
- Azure Blob Storage: Provide the connection string.
- GCP Storage: Configure service account credentials.
- Access databases (e.g., MySQL, PostgreSQL) using JDBC or ODBC connectors.
6. Create and Run a Notebook
Steps:
- Go to the Workspace tab.
- Click Create > Notebook.
- Choose a programming language (Python, Scala, SQL, or R).
- Write your first command, such as:
- Python:
df = spark.read.csv('/path/to/file.csv', header=True) - SQL:
SELECT * FROM table_name
- Python:
- Click Run Cell or press
Shift + Enter.
7. Explore Delta Lake
Delta Lake is a critical feature for reliable data storage and processing.
Example:
- Write data:
df.write.format("delta").save("/mnt/delta/my_table") - Read data:
spark.read.format("delta").load("/mnt/delta/my_table") - Query Delta tables using SQL.
8. Build a Machine Learning Model
Use Databricks’ ML capabilities to build and deploy models.
Example:
- Load a dataset:
from sklearn.datasets import load_iris iris = load_iris(as_frame=True) df = iris['data'] - Train a model:
from sklearn.ensemble import RandomForestClassifier clf = RandomForestClassifier() clf.fit(df.iloc[:, :-1], df.iloc[:, -1]) - Save the model using MLflow:
import mlflow mlflow.sklearn.log_model(clf, "random-forest-model")
9. Schedule and Automate Jobs
- Go to the Jobs tab.
- Click Create Job.
- Add a notebook or custom script.
- Set a schedule (e.g., daily or hourly).
- Monitor job runs for success or failure.
10. Leverage Databricks Features
- Visualizations: Create charts and graphs in notebooks.
- Widgets: Add interactive input elements to notebooks.
- Unity Catalog: Implement data governance.
- Delta Sharing: Share data securely with external users.
11. Learn and Practice
- Official Tutorials: Explore the Databricks Documentation.
- Community Resources: Join the Databricks Community Forum.
- Certifications: Consider pursuing Databricks certifications like:
- Databricks Certified Associate Developer for Apache Spark.
- Databricks Certified Data Engineer Professional.
Detailed Databricks Workflow
The workflow in Databricks is designed to streamline the process of working with data, from ingestion and transformation to analysis, machine learning, and deployment. Below is a step-by-step breakdown of the Databricks workflow:
1. Data Ingestion
Purpose: Bring raw data into Databricks for processing and analysis.
How to Ingest Data:
- From Local Files:
- Navigate to the Data tab in Databricks.
- Click Add Data and upload your file (e.g., CSV, JSON, Parquet).
- Use the uploaded file in notebooks with Spark commands:
df = spark.read.format("csv").option("header", "true").load("/mnt/my_file.csv")
- From Cloud Storage:
- Mount cloud storage (S3, Azure Blob, or GCS) to Databricks File System (DBFS).
dbutils.fs.mount( source="s3a://mybucket", mount_point="/mnt/mybucket", extra_configs={"fs.s3a.access.key": "ACCESS_KEY", "fs.s3a.secret.key": "SECRET_KEY"} ) - Load data using Spark:
df = spark.read.csv("/mnt/mybucket/myfile.csv", header=True)
- Mount cloud storage (S3, Azure Blob, or GCS) to Databricks File System (DBFS).
- From Databases:
- Use JDBC or ODBC to connect to databases like MySQL, PostgreSQL, or SQL Server.
jdbc_url = "jdbc:mysql://hostname:3306/dbname" properties = {"user": "username", "password": "password"} df = spark.read.jdbc(url=jdbc_url, table="table_name", properties=properties)
- Use JDBC or ODBC to connect to databases like MySQL, PostgreSQL, or SQL Server.
2. Data Preparation and Transformation
Purpose: Clean, enrich, and transform data for analysis and machine learning.
Steps:
- Data Cleaning:
- Handle missing values:
df = df.na.fill({"column_name": "default_value"}) - Remove duplicates:
df = df.dropDuplicates(["column_name"])
- Handle missing values:
- Data Transformation:
- Add new columns:
df = df.withColumn("new_column", df["existing_column"] * 2) - Filter rows:
df = df.filter(df["column_name"] > 10)
- Add new columns:
- Data Aggregation:
- Group and summarize:
df.groupBy("group_column").agg({"value_column": "sum"}).show()
- Group and summarize:
- Write Transformed Data:
- Save data back to storage:
df.write.format("parquet").save("/mnt/output")
- Save data back to storage:
3. Exploratory Data Analysis (EDA)
Purpose: Analyze the data to derive insights and prepare it for advanced processing.
Steps:
- Visualize Data:
- Use built-in visualizations in Databricks Notebooks.
- Example: Visualize a bar chart:
display(df.groupBy("category").count())
- Run SQL Queries:
- Use SQL directly in notebooks:
%sql SELECT category, COUNT(*) AS count FROM table GROUP BY category
- Use SQL directly in notebooks:
- Data Sampling:
- Work with a subset of data for faster exploration:
sample_df = df.sample(fraction=0.1)
- Work with a subset of data for faster exploration:
4. Machine Learning and Advanced Analytics
Purpose: Build, train, and deploy machine learning models.
Steps:
- Feature Engineering:
- Transform raw data into features suitable for machine learning.
from pyspark.ml.feature import VectorAssembler assembler = VectorAssembler(inputCols=["col1", "col2"], outputCol="features") df = assembler.transform(df)
- Transform raw data into features suitable for machine learning.
- Train Machine Learning Models:
- Use MLlib or libraries like Scikit-learn:
from pyspark.ml.classification import LogisticRegression lr = LogisticRegression(featuresCol="features", labelCol="label") model = lr.fit(df)
- Use MLlib or libraries like Scikit-learn:
- Track Experiments:
- Use MLflow to log parameters and results:
import mlflow with mlflow.start_run(): mlflow.log_param("param_name", value) mlflow.log_metric("metric_name", value)
- Use MLflow to log parameters and results:
- Deploy Models:
- Save models for deployment:
model.save("/mnt/model")
- Save models for deployment:
5. Job Scheduling and Automation
Purpose: Automate workflows and data pipelines.
Steps:
- Create Jobs:
- Navigate to the Jobs tab.
- Create a new job and attach a notebook or custom script.
- Set Triggers:
- Schedule jobs to run at specific intervals (e.g., daily, hourly).
- Example:
- Input a notebook path.
- Set a cron schedule (e.g.,
0 0 * * *for daily).
- Monitor Jobs:
- View job logs, success/failure states, and execution times.
6. Data Sharing and Collaboration
Purpose: Share insights and data securely within teams or externally.
Steps:
- Create Dashboards:
- Use Databricks’ dashboard functionality to present visualizations and reports.
- Share Notebooks:
- Export notebooks as HTML, IPython, or PDF files.
- Assign permissions to control access (read-only or edit).
- Delta Sharing:
- Share data securely with external users using Delta Sharing:
GRANT SELECT ON table_name TO SHARE share_name
- Share data securely with external users using Delta Sharing:
7. Monitor and Optimize
Purpose: Ensure optimal performance and reliability of workflows.
Steps:
- Cluster Monitoring:
- Use the Cluster UI to check memory usage, CPU, and runtime.
- Enable autoscaling for cost optimization.
- Query Performance Tuning:
- Use the Query Execution Plan to identify bottlenecks.
- Optimize transformations using Spark best practices (e.g., caching, partitioning).
- Audit Logs:
- Enable logs for compliance and tracking changes in workflows.
End-to-End Example Workflow
Scenario: ETL Pipeline with Databricks
- Ingest Data: Load raw data from S3 into a Delta Lake table.
- Transform Data: Clean and enrich the data using PySpark or SQL.
- Analyze Data: Use notebooks to visualize trends and derive insights.
- Model Training: Train a machine learning model on prepared data.
- Deploy Pipeline: Schedule the pipeline as a job to run daily.
- Monitor Performance: Use built-in tools to monitor job execution and cluster metrics.
Detailed Databricks Workflow
The workflow in Databricks is designed to streamline the process of working with data, from ingestion and transformation to analysis, machine learning, and deployment. Below is a step-by-step breakdown of the Databricks workflow:
1. Data Ingestion
Purpose: Bring raw data into Databricks for processing and analysis.
How to Ingest Data:
- From Local Files:
- Navigate to the Data tab in Databricks.
- Click Add Data and upload your file (e.g., CSV, JSON, Parquet).
- Use the uploaded file in notebooks with Spark commands:
df = spark.read.format("csv").option("header", "true").load("/mnt/my_file.csv")
- From Cloud Storage:
- Mount cloud storage (S3, Azure Blob, or GCS) to Databricks File System (DBFS).
dbutils.fs.mount( source="s3a://mybucket", mount_point="/mnt/mybucket", extra_configs={"fs.s3a.access.key": "ACCESS_KEY", "fs.s3a.secret.key": "SECRET_KEY"} ) - Load data using Spark:
df = spark.read.csv("/mnt/mybucket/myfile.csv", header=True)
- Mount cloud storage (S3, Azure Blob, or GCS) to Databricks File System (DBFS).
- From Databases:
- Use JDBC or ODBC to connect to databases like MySQL, PostgreSQL, or SQL Server.
jdbc_url = "jdbc:mysql://hostname:3306/dbname" properties = {"user": "username", "password": "password"} df = spark.read.jdbc(url=jdbc_url, table="table_name", properties=properties)
- Use JDBC or ODBC to connect to databases like MySQL, PostgreSQL, or SQL Server.
2. Data Preparation and Transformation
Purpose: Clean, enrich, and transform data for analysis and machine learning.
Steps:
- Data Cleaning:
- Handle missing values:
df = df.na.fill({"column_name": "default_value"}) - Remove duplicates:
df = df.dropDuplicates(["column_name"])
- Handle missing values:
- Data Transformation:
- Add new columns:
df = df.withColumn("new_column", df["existing_column"] * 2) - Filter rows:
df = df.filter(df["column_name"] > 10)
- Add new columns:
- Data Aggregation:
- Group and summarize:
df.groupBy("group_column").agg({"value_column": "sum"}).show()
- Group and summarize:
- Write Transformed Data:
- Save data back to storage:
df.write.format("parquet").save("/mnt/output")
- Save data back to storage:
3. Exploratory Data Analysis (EDA)
Purpose: Analyze the data to derive insights and prepare it for advanced processing.
Steps:
- Visualize Data:
- Use built-in visualizations in Databricks Notebooks.
- Example: Visualize a bar chart:
display(df.groupBy("category").count())
- Run SQL Queries:
- Use SQL directly in notebooks:
%sql SELECT category, COUNT(*) AS count FROM table GROUP BY category
- Use SQL directly in notebooks:
- Data Sampling:
- Work with a subset of data for faster exploration:
sample_df = df.sample(fraction=0.1)
- Work with a subset of data for faster exploration:
4. Machine Learning and Advanced Analytics
Purpose: Build, train, and deploy machine learning models.
Steps:
- Feature Engineering:
- Transform raw data into features suitable for machine learning.
from pyspark.ml.feature import VectorAssembler assembler = VectorAssembler(inputCols=["col1", "col2"], outputCol="features") df = assembler.transform(df)
- Transform raw data into features suitable for machine learning.
- Train Machine Learning Models:
- Use MLlib or libraries like Scikit-learn:
from pyspark.ml.classification import LogisticRegression lr = LogisticRegression(featuresCol="features", labelCol="label") model = lr.fit(df)
- Use MLlib or libraries like Scikit-learn:
- Track Experiments:
- Use MLflow to log parameters and results:
import mlflow with mlflow.start_run(): mlflow.log_param("param_name", value) mlflow.log_metric("metric_name", value)
- Use MLflow to log parameters and results:
- Deploy Models:
- Save models for deployment:
model.save("/mnt/model")
- Save models for deployment:
5. Job Scheduling and Automation
Purpose: Automate workflows and data pipelines.
Steps:
- Create Jobs:
- Navigate to the Jobs tab.
- Create a new job and attach a notebook or custom script.
- Set Triggers:
- Schedule jobs to run at specific intervals (e.g., daily, hourly).
- Example:
- Input a notebook path.
- Set a cron schedule (e.g.,
0 0 * * *for daily).
- Monitor Jobs:
- View job logs, success/failure states, and execution times.
6. Data Sharing and Collaboration
Purpose: Share insights and data securely within teams or externally.
Steps:
- Create Dashboards:
- Use Databricks’ dashboard functionality to present visualizations and reports.
- Share Notebooks:
- Export notebooks as HTML, IPython, or PDF files.
- Assign permissions to control access (read-only or edit).
- Delta Sharing:
- Share data securely with external users using Delta Sharing:
GRANT SELECT ON table_name TO SHARE share_name
- Share data securely with external users using Delta Sharing:
7. Monitor and Optimize
Purpose: Ensure optimal performance and reliability of workflows.
Steps:
- Cluster Monitoring:
- Use the Cluster UI to check memory usage, CPU, and runtime.
- Enable autoscaling for cost optimization.
- Query Performance Tuning:
- Use the Query Execution Plan to identify bottlenecks.
- Optimize transformations using Spark best practices (e.g., caching, partitioning).
- Audit Logs:
- Enable logs for compliance and tracking changes in workflows.
End-to-End Example Workflow
Scenario: ETL Pipeline with Databricks
- Ingest Data: Load raw data from S3 into a Delta Lake table.
- Transform Data: Clean and enrich the data using PySpark or SQL.
- Analyze Data: Use notebooks to visualize trends and derive insights.
- Model Training: Train a machine learning model on prepared data.
- Deploy Pipeline: Schedule the pipeline as a job to run daily.
- Monitor Performance: Use built-in tools to monitor job execution and cluster metrics.
Would you like an example notebook for any specific part of the workflow?