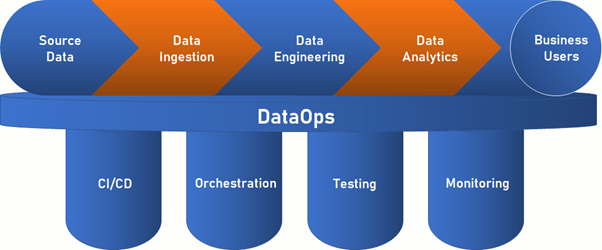
What Is DataOps?
DataOps is a collection of technical practices, workflows, cultural norms, and architectural patterns that enable:
- Rapid innovation and experimentation delivering new insights to customers with increasing velocity
- Extremely high data quality and very low error rates
- Collaboration across complex arrays of people, technology, and environments
- Clear measurement, monitoring, and transparency of results
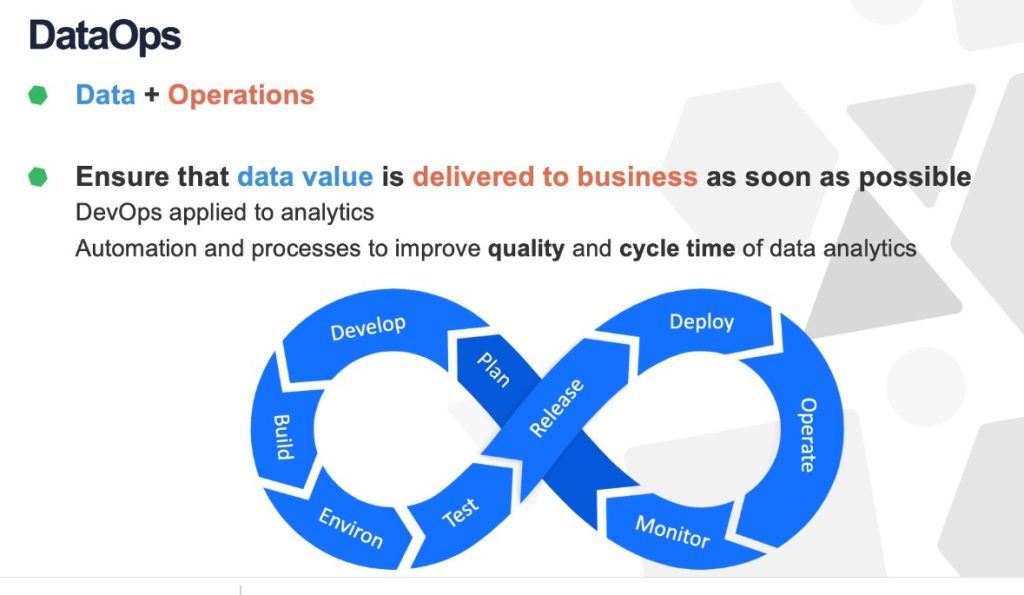
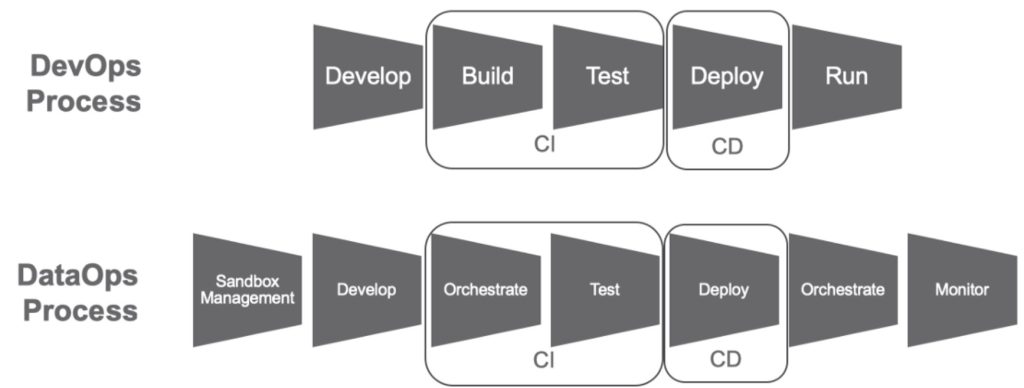
DataOps can yield an order of magnitude improvement in quality and cycle time when data teams utilize new tools and methodologies. DevOps optimizes the software development pipeline.
DataOps is a collaborative data management practice focused on improving the communication, integration and automation of data flows between data managers and data consumers across an organization. The goal of DataOps is to deliver value faster by creating predictable delivery and change management of data, data models and related artifacts. DataOps uses technology to automate the design, deployment and management of data delivery with appropriate levels of governance, and it uses metadata to improve the usability and value of data in a dynamic environment.
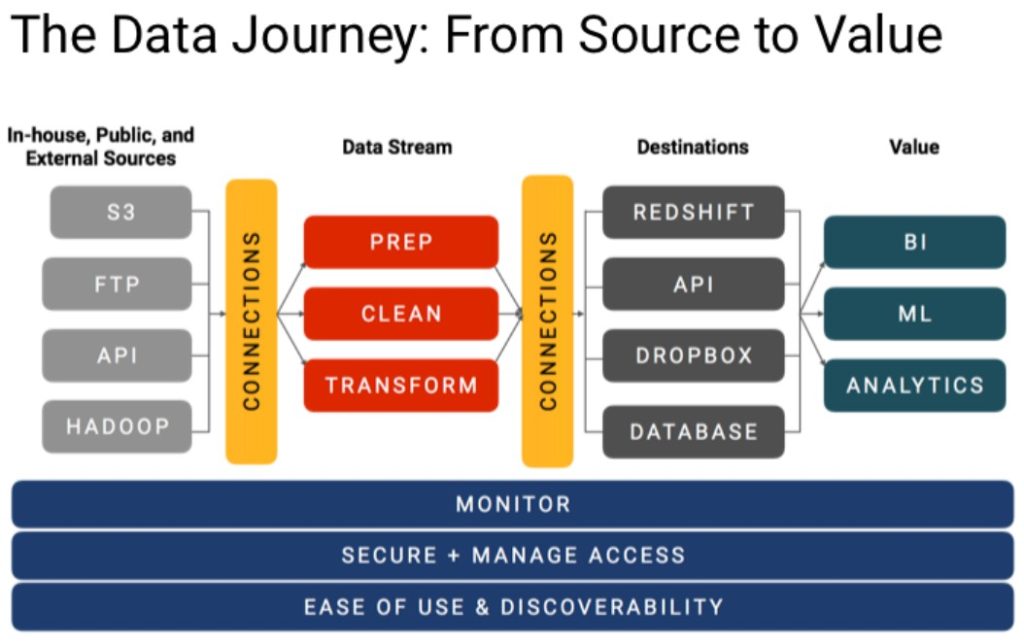
Evoution of DataOps
We trace the origins of DataOps to the pioneering work of management consultant W. Edwards Deming, often credited for inspiring the post-World War II Japanese economic miracle. The manufacturing methodologies riding Deming’s coattails are now being widely applied to software development and IT. DataOps further brings these methodologies into the data domain. In a nutshell, DataOps applies Agile development, DevOps and lean manufacturing to data analytics development and operations. Agile is an application of the Theory of Constraints to software development, i.e., smaller lot sizes decrease work-in-progress and increase overall manufacturing system throughput. DevOps is a natural result of applying lean principles (e.g., eliminate waste, continuous improvement, broad focus) to application development and delivery. Lean manufacturing also contributes a relentless focus on quality, using tools such as statistical process control, to data analytics.
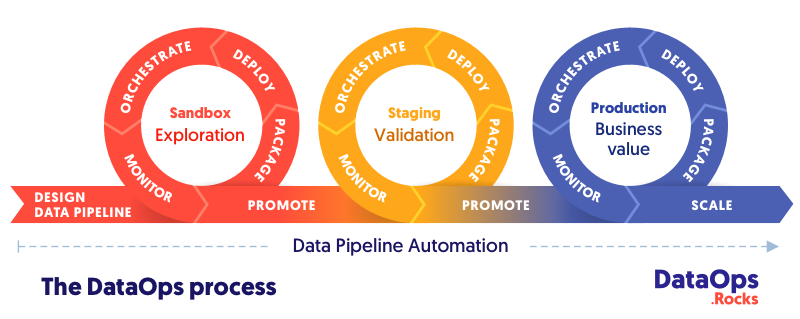
What problem is DataOps trying to solve?
Data teams are constantly interrupted by data and analytics errors. Data scientists spend 75% of their time massaging data and executing manual steps. Slow and error-prone development disappoints and frustrates data team members and stakeholders. Lengthy analytics cycle time occurs for a variety of reasons:
- Poor teamwork within the data team
- Lack of collaboration between groups within the data organization
- – Waiting for IT to disposition or configure system resources
- Waiting for access to data
- Moving slowly and cautiously to avoid poor quality
- Requiring approvals, such as from an Impact Review Board
- Inflexible data architectures
- Process bottlenecks
- Technical debt from previous deployments
- Poor quality creating unplanned work
Top DataOps Tools in 2023
- Models & Architecture – DataOps Concept and Foundation
- Platform – Operating Systems – Centos/Ubuntu & VirtualBox & Vagrant
- Platform – Cloud – AWS
- Platform – Containers – Docker
- Planning and Designing – Jira & Confulence
- Programming Language – Python
- Source Code Versioning – Git using Github
- Container Orchestration – Kubernetes & Helm Introduction
- Database – Mysql
- Database – postgresql
- Data Analystics Engine – Apache Spark
- Reporting – Grafana
- ETL Tools – Apache Kafka
- Bigdata – Apache Hadoop
- DataOps Integration – Jenkins
- Big Data Tools for Visualization – Microsoft PowerBI
- Big Data Tools for Visualization – Tableau